
在探讨大数据生态系统中,Flume和Kafka的结合使用成为了实时数据处理领域的一个重要话题,这种结合不仅提高了数据处理的效率,还增强了系统的可靠性和容错能力,下面将深入分析Flume与Kafka结合使用的各个方面,并探讨它们如何协同工作以实现高效的数据流处理。
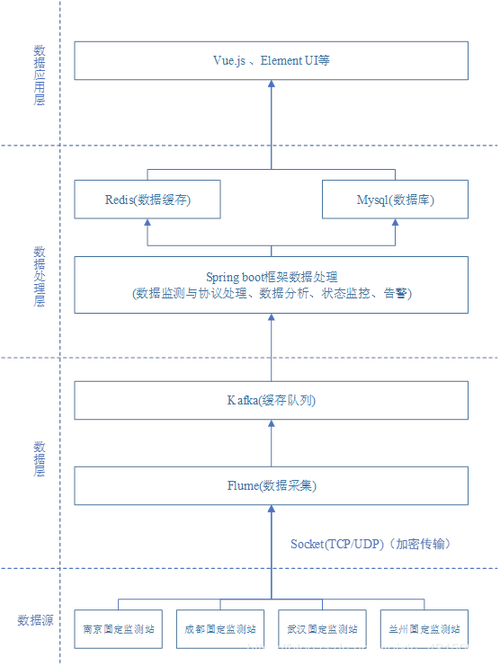

需要了解Flume和Kafka各自的作用以及它们的基本配置方式,Flume是一个分布式、可靠且可用的服务,用于有效地收集、聚合和移动大量日志数据,而Kafka则是一个高吞吐量的分布式消息系统,适合处理实时数据流,在配置Flume与Kafka时,Kafka可以作为Flume的数据源(source),使得Flume能够消费Kafka中的消息数据。
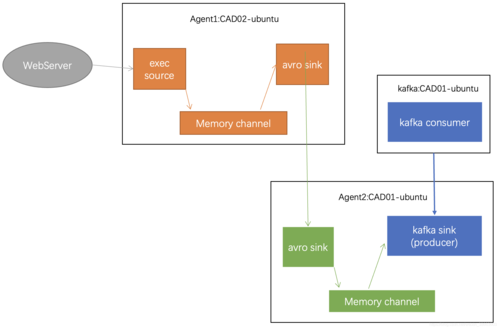
详细解析Flume和Kafka的配置方法,在Flume的配置文件中,需要指定source、sink和channel的名称和类型,可以将Flume的source类型设置为KafkaSource,这样就可以从Kafka的指定主题中读取数据,也需要配置Kafka的相关参数,如bootstrap.servers、topic等,以确保Flume能正确连接到Kafka并消费数据。
而在安全性方面,特别是在涉及到MRS(MapR Streams)的环境中,Flume客户端对接安全的Kafka也提供了详细的指导,这包括创建jaas.conf文件来配置安全认证信息,确保Flume可以安全地连接到Kafka服务。
Flume和Kafka的结合使用通常是为了完成实时流式的日志处理,其中Kafka作为一个消息缓存队列,解决了数据从源头到处理过程中的速度不匹配问题,通过将数据一方面同步到HDFS进行离线计算,另一方面进行实时计算,实现了数据的多分发功能。
在此基础上,可以看到Flume和Kafka的组合为实时数据处理提供了强大的支持,它们不仅优化了数据处理流程,还通过提供数据缓存和异步处理机制,增强了整个系统的灵活性和可靠性。
在使用这两种技术时,也需要注意一些关键的问题。
确保Kafka和Flume之间的版本兼容性,避免因版本差异导致的集成问题。
监控数据流的稳定性和性能,及时调整配置以适应不同的数据负载和处理需求。
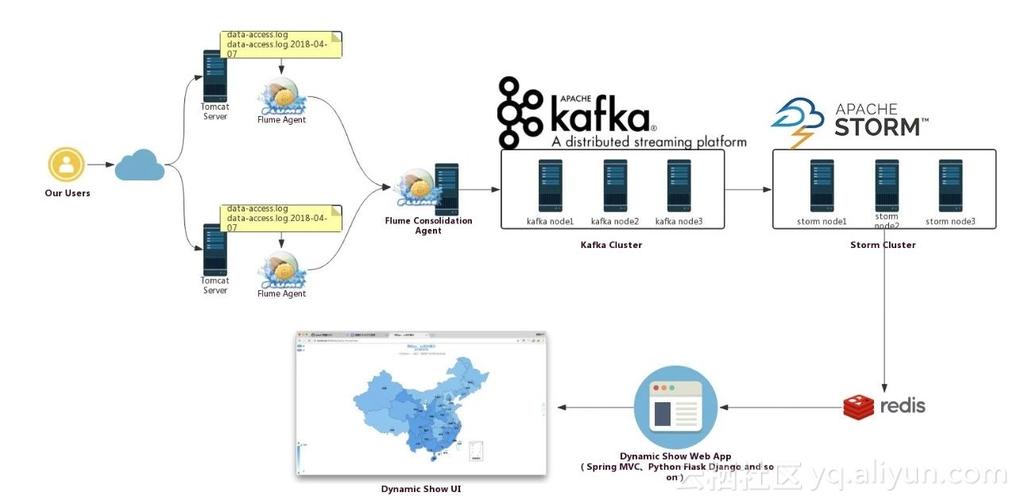
Flume和Kafka的结合使用为实时数据处理提供了一个高效、可靠的解决方案,通过合理的配置和管理,可以充分利用这两者的优势,实现数据的高效采集、传输和处理,满足现代大数据处理的需求,这不仅体现了技术的先进性,也展示了在解决实际问题时的灵活性和创新性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复