
分布式消息系统(Kafka)详解

基础概念
分布式消息服务(Distributed Message Service,简称DMS),是一种基于高可用分布式集群技术的消息中间件服务,它利用分布式技术实现大规模的数据处理与通信,通过消息队列的形式提供可靠且可扩展的托管服务,用于收发和存储消息。
Kafka的基础架构
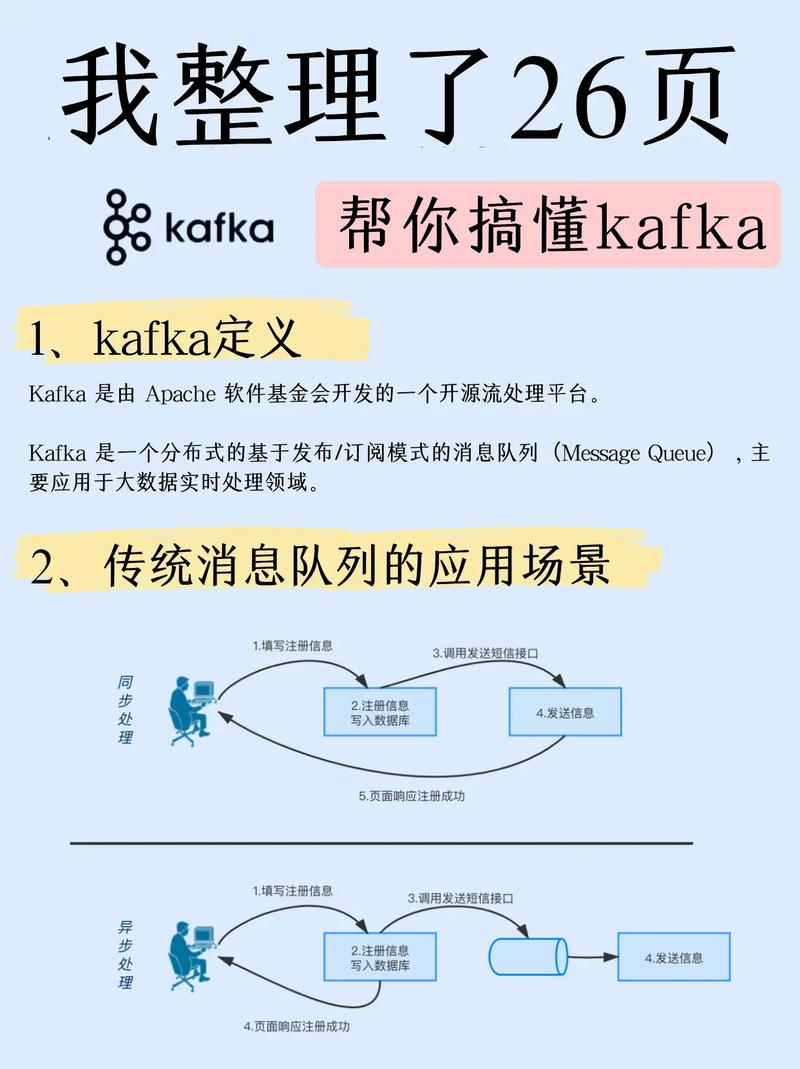
1、Broker:Kafka集群中运行Kafka实例的服务器称为Broker。
2、Topic:发送到Kafka集群的消息归属于一个类别,这个类别被称为Topic。
3、Partition:为了保证更高的吞吐量和可扩展性,每个Topic被分为多个分区。
4、Producer:负责发布消息到Topic的应用程序。
5、Consumer:负责从Topic订阅和接收消息的应用程序。
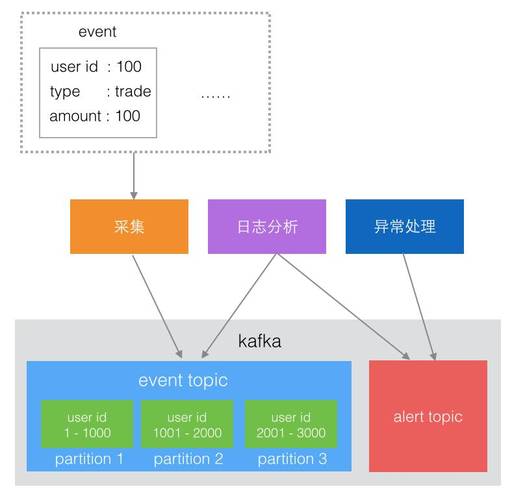
6、Consumer Group:一组消费者共同协作消费Topic中的消息。
7、Replica:每个Partition可以有多个副本以提高容错性。
8、Leader:在多个副本中,负责读写操作的被称为Leader。
9、Follower:追随Leader,复制数据以备不时之需。
10、Zookeeper:管理Kafka集群中的Broker,并处理其他控制任务。
Kafka的核心特性
高可靠性:通过消息持久化和多副本策略保证消息不丢失。
高吞吐:支持批量发送和拉取消息,达到高系统吞吐量。
分布式:天生的分布式设计,支持横向扩展。
可扩展性:无需停机即可增加机器扩展集群。
消息顺序性:保证在一个分区内消息的发送和消费顺序。
回溯消费:Consumer可以倒回至任意已消费的消息起始位置重新消费。
Kafka的应用场景
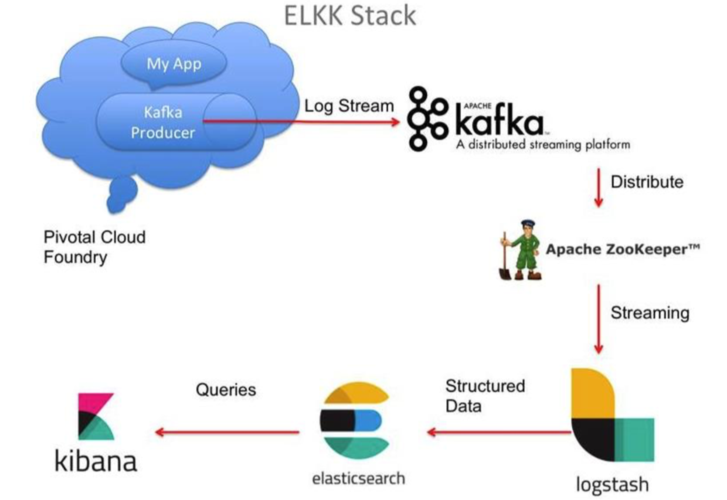
日志收集:集中处理和分析来自不同系统的日志。
消息驱动的微服务:解耦服务之间的通信。
流处理:实时处理和分析数据流。
事件源系统:构建和管理应用中的事件。
Kafka的安装与配置
1、环境准备:安装Java环境和配置系统变量。
2、下载Kafka:从Apache官网或镜像站点下载。
3、启动Zookeeper:作为Kafka的依赖组件。
4、配置Broker:编辑配置文件,如config/server.properties。
5、启动Kafka Server:使用脚本启动Kafka服务。
6、创建Topic:通过命令行工具创建Topic。
7、发送与接收消息:编写Producer和Consumer程序进行测试。
注意事项与性能优化
合理设置分区数量:根据实际需求调整,平衡负载和并行度。
内存与磁盘优化:适当调整JVM参数和磁盘I/O策略。
网络调优:确保低延迟的网络连接。
安全设置:配置SSL/TLS加密,保障数据传输安全。
归纳与最佳实践
监控告警:实施监控方案,及时发现并处理问题。
版本升级:跟随社区更新,获取新特性及性能改进。
备份与恢复:定期备份数据,并验证恢复流程。
文档与社区:充分利用官方文档和社区资源解决遇到的问题。
相关问题解答
1、Q: Kafka如何保证消息的顺序?
A: Kafka保证在一个分区内消息的发送和消费顺序,由于一个Topic内部消息可以分布在不同的分区,所以仅在单个分区级别上保证顺序,若需整体有序,应设计为单分区Topic,但可能会影响吞吐量和容错能力。
2、Q: Kafka是否适用于所有场景?
A: 并非所有场景都适合使用Kafka,若需要严格的消息排序或者非常强的一致性保证,则应考虑其他MQ方案,对于非实时的数据处理,可能也不需要Kafka的高吞吐量特性。
通过上述的详细介绍,相信读者已经对分布式消息系统特别是Apache Kafka有了更深入的了解,在实际应用中,应根据具体需求选择最合适的消息中间件,并不断优化和调整以满足业务的发展。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复