
MapReduce服务(MRS)是华为云提供的一种托管的Hadoop和Spark集群服务,它允许用户在云上轻松地运行大数据处理任务,无需担心底层基础设施的搭建和维护,Kafka是一个分布式流数据平台,常用于构建实时数据管道和流式应用程序,将MapReduce与Kafka结合使用,可以有效地处理和分析流数据。
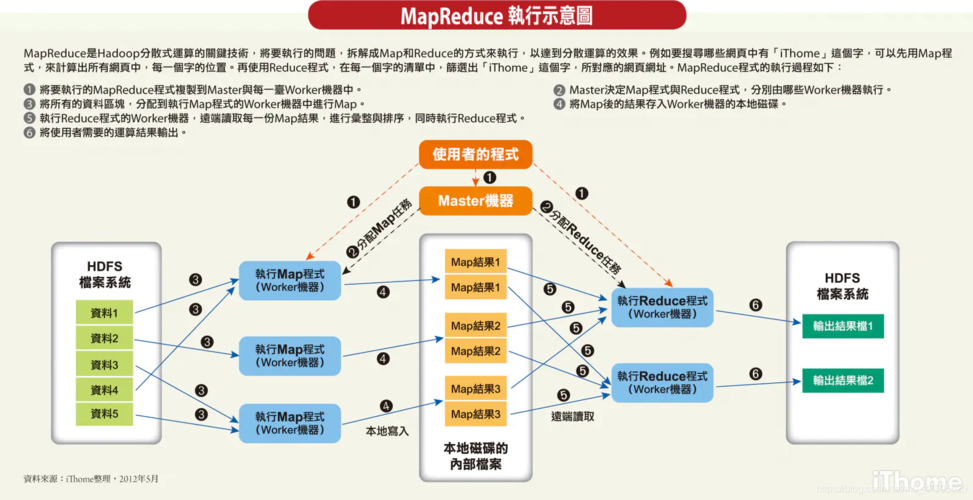

MRS的主要特点:
全托管: 用户不需要管理底层的Hadoop或Spark集群,华为云会负责所有的运维工作。
弹性伸缩: 根据数据处理需求,用户可以灵活选择计算和存储资源,实现资源的自动伸缩。
安全性: 提供多种安全措施,包括VPC网络隔离、SSL加密传输等。
高性能: 优化的Hadoop和Spark环境,确保数据处理任务高效执行。
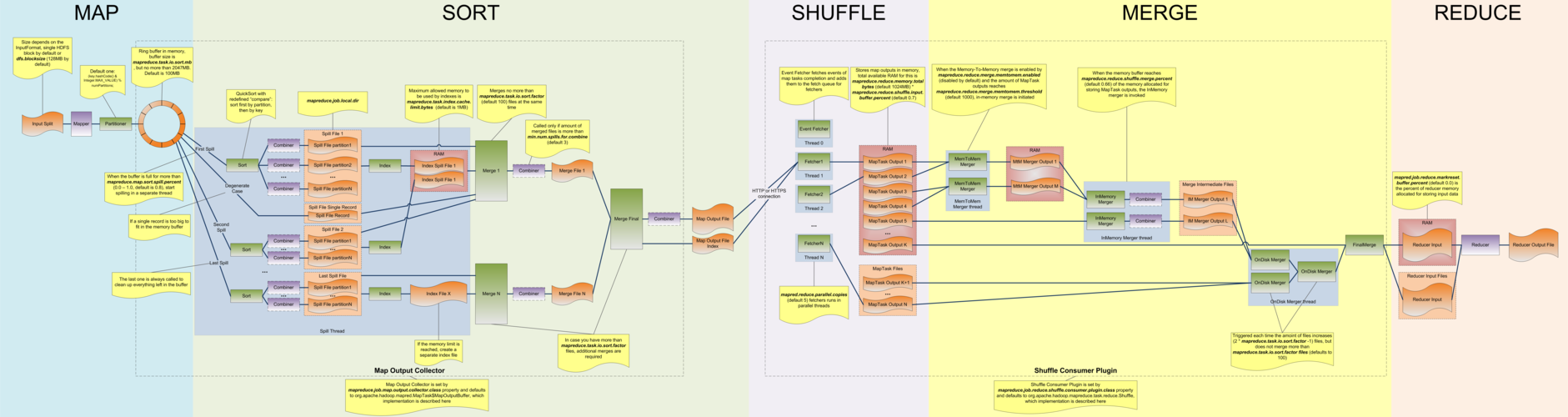
Kafka的关键特性:
高吞吐量: 能够处理几十万条消息的每秒写入。
可扩展性: Kafka集群可以横向扩展,以支持更大的数据负载。
持久性: 消息被持久化到硬盘,可以配置保留策略。
分布式: Kafka天然支持分布式,可以在多个服务器上运行。
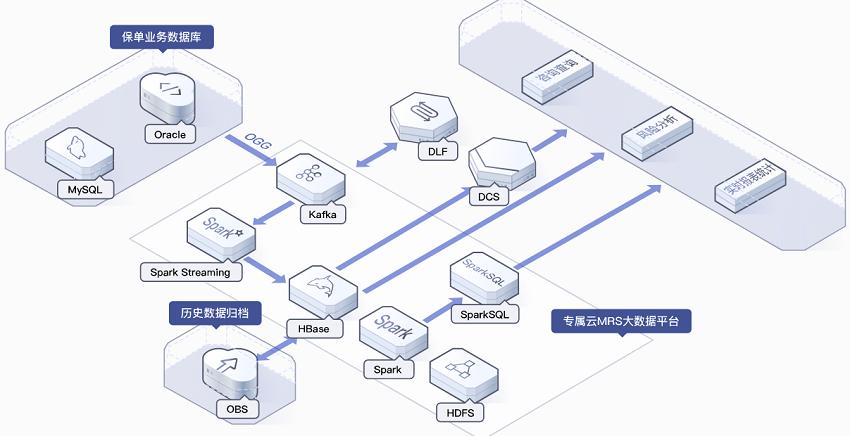
MRS与Kafka的集成:
数据流入: 通过Kafka作为数据源,将实时数据流导入到MapReduce作业中进行处理。
数据处理: 利用MapReduce的强大处理能力,对Kafka中的数据进行批量处理和分析。
结果输出: 处理后的数据可以写回到Kafka或其他系统中,供进一步分析或实时展示。
使用场景示例:
1、日志分析: 收集来自不同服务器的日志数据,通过Kafka进入MRS进行实时分析,快速发现系统问题。
2、实时监控: 利用Kafka收集监控数据,MRS进行实时数据分析,生成报警或报告。
相关技术比较:
| 技术 | Kafka | MapReduce服务 (MRS) |
| 类型 | 分布式流数据平台 | 大数据处理服务 |
| 适用场景 | 实时数据采集、消息传递 | 大规模数据处理、分析 |
| 扩展性 | 高 | 中等(依赖于云服务提供商的扩展能力) |
| 数据处理速度 | 高(实时) | 中等(批处理) |
| 运维要求 | 需要专业团队维护 | 低(全托管服务) |
| 成本 | 变动成本(根据使用量) | 固定成本(预付费或按需付费) |
相关问题与解答:
Q1: MRS如何处理Kafka中的流数据?
A1: MRS可以通过集成Kafka客户端库,消费Kafka主题中的消息,这些消息作为输入提供给MapReduce作业,经过处理后,可以将结果写回到Kafka或其他存储系统中。
Q2: 使用MRS和Kafka集成的优势是什么?
A2: 这种集成提供了实时数据处理的能力,同时降低了运维复杂性,用户可以专注于业务逻辑的实现,而不必担心底层集群的管理,它还提供了高吞吐量和良好的扩展性,适合处理大规模的流数据。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复