
分布式消息产品_分布式消息(Kafka)是一种高吞吐量、高可用的消息中间件服务,被广泛应用于构建实时数据管道、流式数据处理、第三方解耦、以及流量削峰去谷等关键业务场景,下面将深入探讨Kafka作为分布式消息产品的多个方面,以期对您有一个全面而深入的介绍:

1、高吞吐量和高性能
设计目标:Kafka设计之初的主要目标就是处理高吞吐量的数据流,通过优化磁盘I/O操作和批处理消息发送,Kafka能够高效地处理大规模消息传输。
性能表现:实际生产环境中,Kafka能稳定支撑每秒数百万消息的发布与消费,这对于需要处理大量实时数据的企业来说至关重要。
2、高可靠性和数据持久性
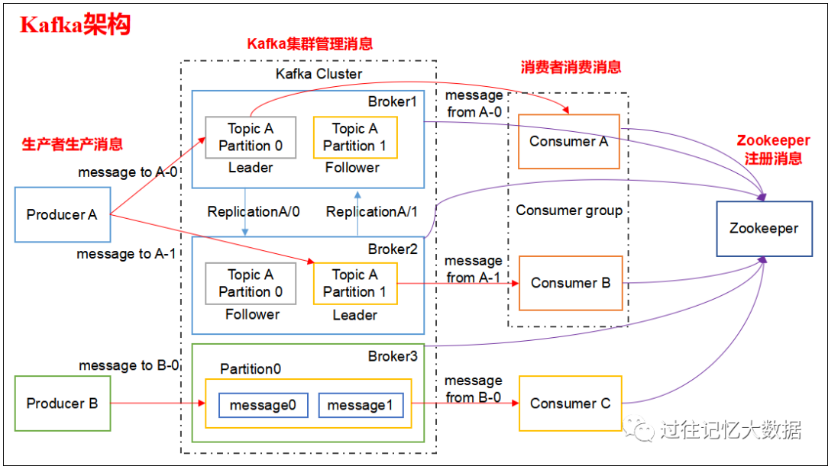
数据存储:Kafka将消息持久化存储在分布式系统的多个节点上,确保了数据的可靠性和持久性,即使系统出现故障,消息也不会丢失。
副本机制:Kafka通过多副本机制来提高数据的可用性和耐久性,用户可以配置数据副本的数量,以实现更高级别的数据安全保证。
3、解耦和扩展性
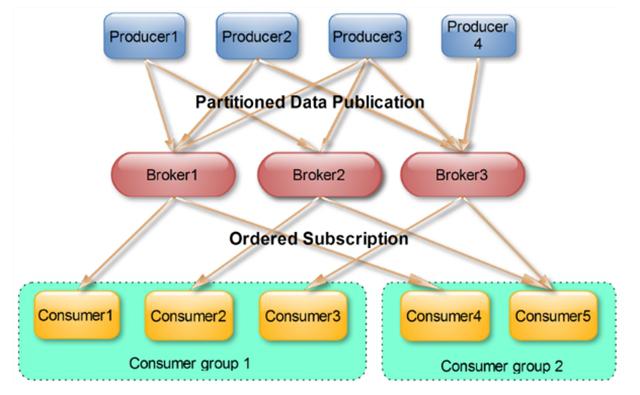
系统解耦:作为一种分布式消息系统,Kafka支持多个生产者和消费者之间的解耦,提高了系统的灵活性和可维护性。
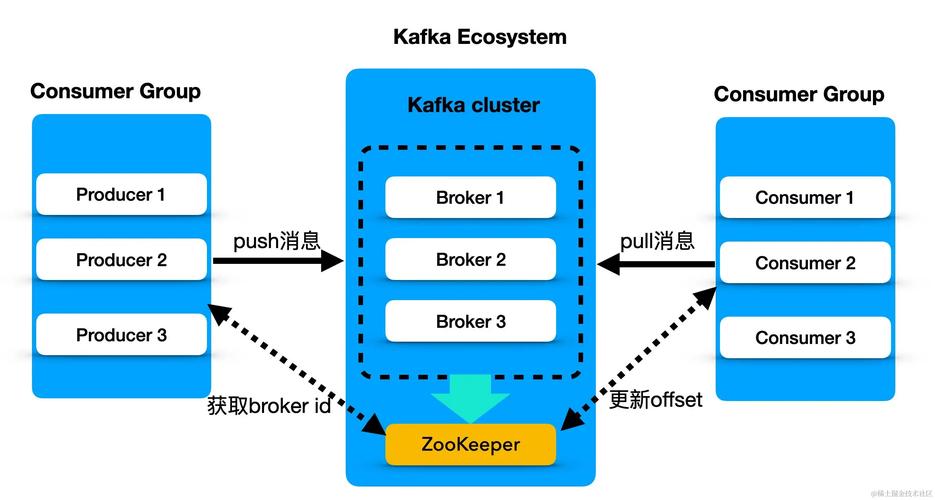
水平扩展:随着业务量的增长,Kafka集群可以通过增加更多的服务器来进行水平扩展,以应对不断增长的数据量和访问压力。
4、用例和场景适用性
实时数据处理:Kafka非常适合于需要快速处理实时数据流的场景,如金融交易数据的实时处理、社交媒体内容的实时更新等。
大数据处理:由于其高吞吐量的特性,Kafka经常与大数据处理技术如Apache Hadoop、Apache Spark等结合使用,用于处理和分析大规模的数据集。
5、兼容性和社区生态
API兼容:许多Kafka分布式消息服务版本兼容开源Kafka API,使得企业可以在不同环境下使用统一的应用程序接口,便于开发和迁移。
社区和生态:Kafka拥有活跃的开发者社区,不断有新的功能和改进被贡献,而且生态系统丰富,有许多配套的工具和插件可用于优化Kafka的使用。
Apache Kafka及其分布式消息服务版本是一款强大的消息中间件,适用于需要高性能、高可靠性、高可扩展性的实时数据处理场景,通过合理的架构设计和配置,Kafka能够在现代分布式系统中扮演关键角色,帮助企业和开发者有效管理数据流,实现业务的快速迭代和扩展。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复