
Flume日志采集系统是一个分布式、可靠、高可用的海量日志采集、聚合和传输的系统,在大数据时代,日志数据的采集与处理变得尤为重要,Flume作为解决这个问题的一个方案,被设计用于高效地从各种源处采集日志数据,并将这些数据传输到多种外部存储系统中,由于其分布式、可靠和高可用的特性,Flume被广泛应用于大数据分析的场景中。
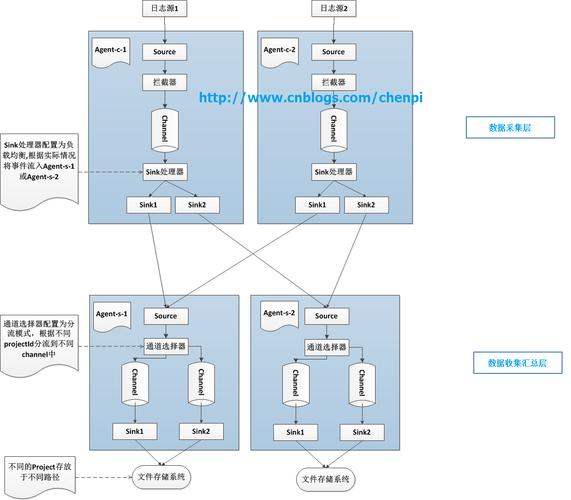

Flume的核心是agent,每一个agent都是数据传递的一个环节,每个agent内部由三个主要组件构成:sources、channels和sinks,Sources负责接收数据,channels作为临时存储保证数据的传输,sinks则将数据发送到下一个agent或者最终的存储系统。
Flume具备灵活的配置选项,可以根据具体的业务需求进行定制,通过简单配置,Flume可以实现对文件、socket数据包等不同形式源数据的采集,并将数据输出到HDFS、HBase、Hive、Kafka等外部存储系统,Flume的流式架构使得数据处理流程更加灵活和高效,Flume的插拔式软件架构使得所有组件都是可定制的,用户可以根据自己的特殊需求进行个性化扩展。
Flume的发展经历了两个主要版本,即Flume 0.9x(Flumeog)和Flume 1.x(Flumeng),Flumeng相对于Flumeog而言,有了显著的改进,比如改进了架构和增加了新的特性,这使得Flumeng成为了更优的选择,Flume不仅仅局限于日志数据的采集,由于其数据源可以自由定制,Flume也适用于收集网络流量数据、社交媒体数据、电子邮件消息以及几乎任何其他类型的数据。
Flume作为一个高可用、高可靠且分布式的日志采集系统,提供了强大的数据采集、聚合和传输能力,通过简单的配置就可以实现一般采集需求,而对于特殊的场景也有良好的自定义扩展能力,Flume的流式架构和插拔式软件架构使得它非常灵活且易于扩展,正是由于这些特性,Flume在大数据领域有着广泛的应用前景,无论是对于日志数据的采集还是对于其他类型数据的处理,Flume都展现出了其不可替代的价值。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复