
FPGrowth算法是一种高效的频繁项集挖掘算法,适用于大规模数据集。MapReduce编程模型可以用于实现FPGrowth算法的并行化处理,提高算法在分布式环境下的性能。
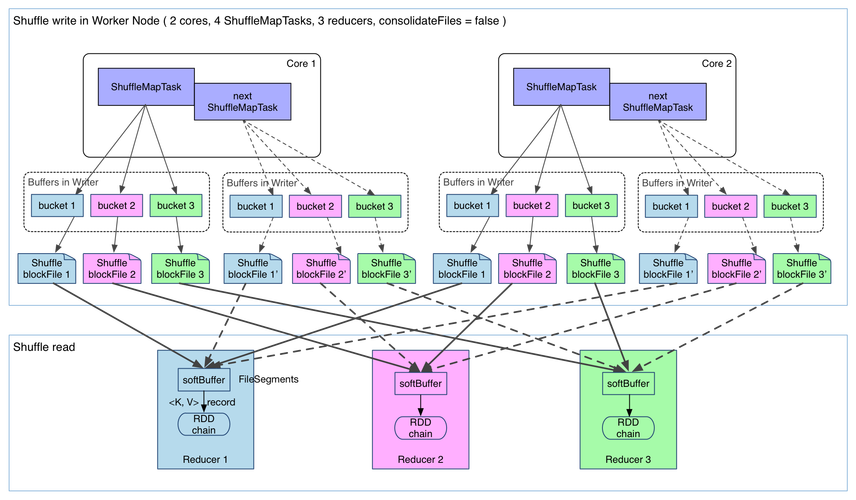
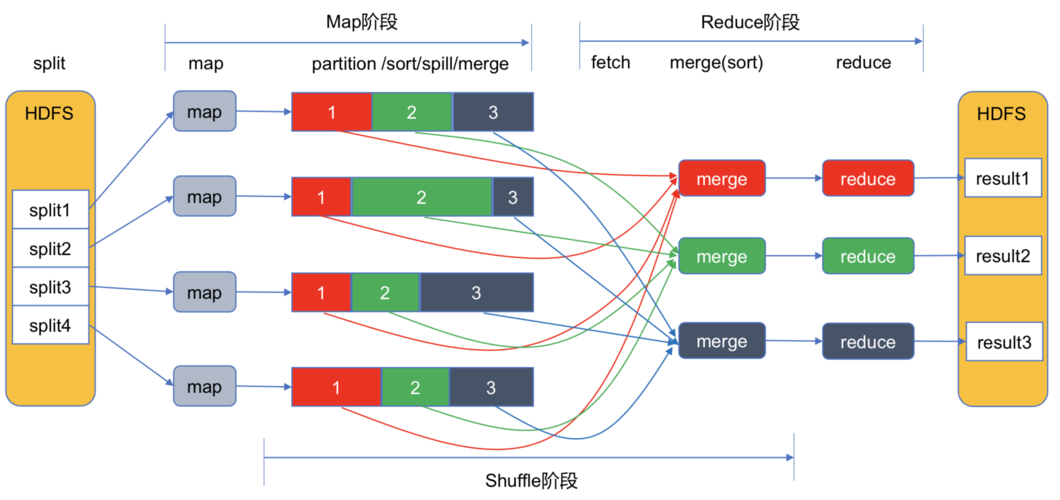
FPGrowth算法是一种用于挖掘频繁项集的高效算法,它通过构建FP树(Frequent Pattern Tree)来压缩数据,并在此基础上进行挖掘,MapReduce是一种分布式计算框架,可以将大规模数据集分解为多个小任务并行处理,将FPGrowth算法与MapReduce结合,可以实现在分布式环境下对大规模数据集进行频繁项集挖掘。

(图片来源网络,侵删)
以下是使用MapReduce实现FPGrowth算法的详细步骤:
1、数据预处理:将原始数据集转换为适合FPGrowth算法处理的格式,例如将每条交易记录转换为<item, count>的形式。
2、Map阶段:将预处理后的数据分片,每个分片由一个Mapper处理,Mapper的任务是统计每个分片中各个项的出现次数,并将结果输出为<item, count>的形式。
3、Reduce阶段:将Map阶段的输出按照item进行聚合,得到全局的项计数,然后根据预设的最小支持度阈值,筛选出频繁项集。
4、构建FP树:根据筛选出的频繁项集,构建FP树,首先创建一个空的根节点,然后遍历每个交易记录,将其包含的频繁项按照支持度降序排列,逐个插入到FP树中。
5、挖掘FP树:对构建好的FP树进行挖掘,找出所有的频繁项集,这个过程可以通过递归地构建条件FP树和条件基来实现。
6、输出结果:将挖掘到的频繁项集输出为最终结果。
以下是使用Python实现的FPGrowth算法的伪代码:
(图片来源网络,侵删)
def fp_growth(data, min_support):
# 构建FP树
def build_fp_tree(data, min_support):
pass
# 挖掘FP树
def mine_fp_tree(tree, header_table, prefixpath, frequent_items):
pass
# 获取频繁项集
def get_frequent_items(data, min_support):
pass
# 主函数
frequent_items = get_frequent_items(data, min_support)
fp_tree = build_fp_tree(data, min_support, frequent_items)
mine_fp_tree(fp_tree, frequent_items[:], [], frequent_items)
调用fp_growth函数,传入数据集和最小支持度阈值
fp_growth(data, min_support) 注意:这里的代码仅为伪代码,实际实现时需要根据具体需求进行修改和完善。
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复