
Kafka数据读取到RDS的MapReducer流程
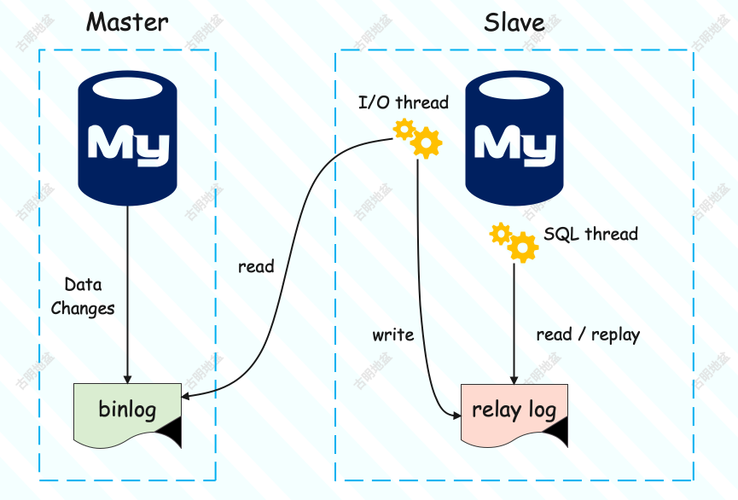

在大数据生态系统中,Apache Kafka常用于构建实时数据流管道,结合Hadoop MapReduce框架,可以将Kafka中的数据高效地导入关系型数据库服务(RDS),下面详细介绍从Kafka读取数据并写入RDS的步骤和相关技术细节。
Kafka消费者设置
需要配置一个Kafka消费者,以便从指定的topic中拉取数据,这通常涉及到以下参数的配置:
bootstrap.servers: Kafka集群地址
group.id: 消费者组ID
auto.offset.reset: 消费偏移量重置策略
key.deserializer和value.deserializer: 键值对的反序列化类
MapReduce作业设计
设计MapReduce作业来处理Kafka消费者拉取的数据,这个作业通常包括两个阶段:Map阶段和Reduce阶段。
Map阶段
在Map阶段,每个Mapper会接收到来自Kafka的数据,并对这些数据进行预处理,比如数据清洗、格式转换等,处理后的数据会被发送到Reduce阶段。
Reduce阶段
Reduce阶段负责将Map阶段输出的数据聚合或汇总,并生成最终要写入RDS的数据,这个阶段可以执行复杂的计算和数据合并操作。
写入RDS
最后一步是将Reduce阶段的输出结果写入RDS,这通常通过JDBC连接实现,需要在Hadoop集群上配置相应的数据库驱动,并在MapReduce代码中编写与数据库交互的逻辑。
技术细节和最佳实践
Kafka消费者并行度
为了提高数据处理的效率,可以通过增加消费者并行度来实现,这通常通过调整max.poll.records和fetch.max.bytes参数来完成。
MapReduce调优
合理设置Mapper和Reducer数量:根据集群资源和数据量大小调整,以获得最佳性能。
内存和I/O优化:调整JVM堆大小和MapReduce任务的I/O缓冲区大小,减少GC开销和提高I/O效率。
RDS写入优化
批量处理:尽可能批量插入或更新数据,以减少网络开销和数据库负载。
并发控制:合理设置并发连接数,避免过多连接耗尽数据库资源。
问题与解答
Q1: Kafka消费者如何确保数据的一致性和可靠性?
A1: Kafka消费者通过维护消费偏移量来确保数据的一致性,消费者每次成功处理消息后,都会提交当前的消费偏移量,如果消费者失败,它可以从最后一次提交的偏移量开始重新消费,从而避免数据丢失。
Q2: 如何处理MapReduce作业中的故障恢复?
A2: Hadoop MapReduce框架自带故障恢复机制,如果某个任务失败,框架会自动重新调度该任务到其他节点,可以通过设置合适的重试次数和失败策略来进一步保障作业的稳定性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复