
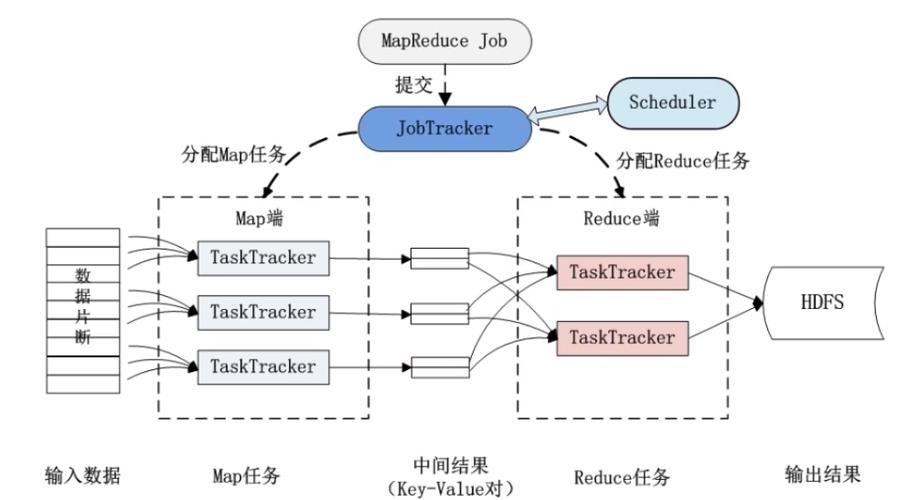
MapReduce是一种编程模型,用于处理和生成大数据集,它是在分布式计算环境中实现的,其中数据存储在不同的节点上,MapReduce程序至少包括两个部分:一个映射函数(Map),它处理输入数据并生成中间键值对;还有一个归约函数(Reduce),它处理具有相同键的所有值,并将它们合并成一个较小的值集合。

MapReduce 工作原理
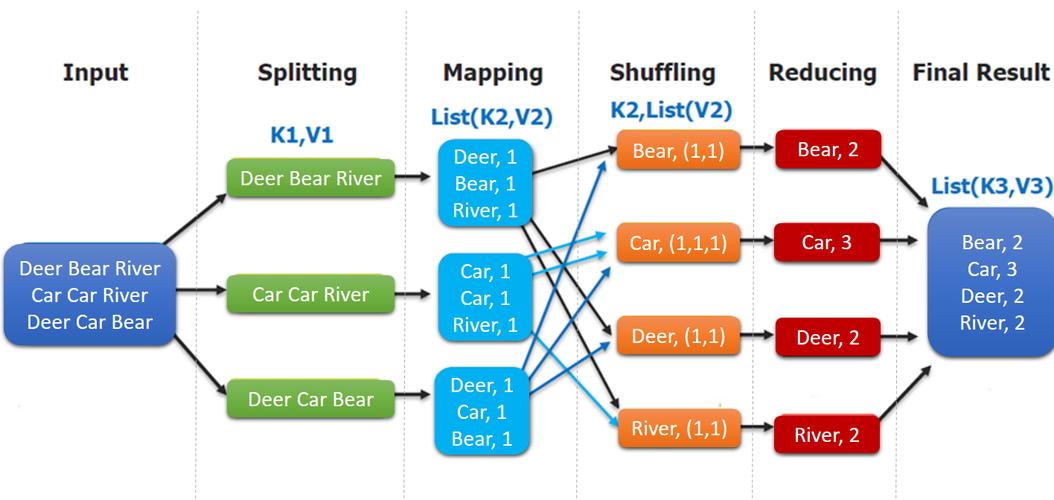
Map阶段
输入分片:输入文件被分成多个分片,每个分片由一个Map任务处理。
映射函数:Map任务从输入数据中提取出键值对,经过处理后生成一组中间键值对。
局部排序:这些中间键值对会被按照键进行排序。
分区:排序后的键值对根据分区函数被分配到不同的Reduce任务。
Shuffle阶段
数据传输:Map任务将它们的输出发送给执行Reduce任务的节点。
全局排序:Reduce端可能会对收到的数据按键进行排序,以确保数据的顺序性。
Reduce阶段
归约函数:Reduce任务遍历所有中间数据,对每个唯一的键应用归约函数,并输出最终结果。
输出
输出结果通常写入到HDFS(Hadoop Distributed File System)或其他分布式文件系统中。
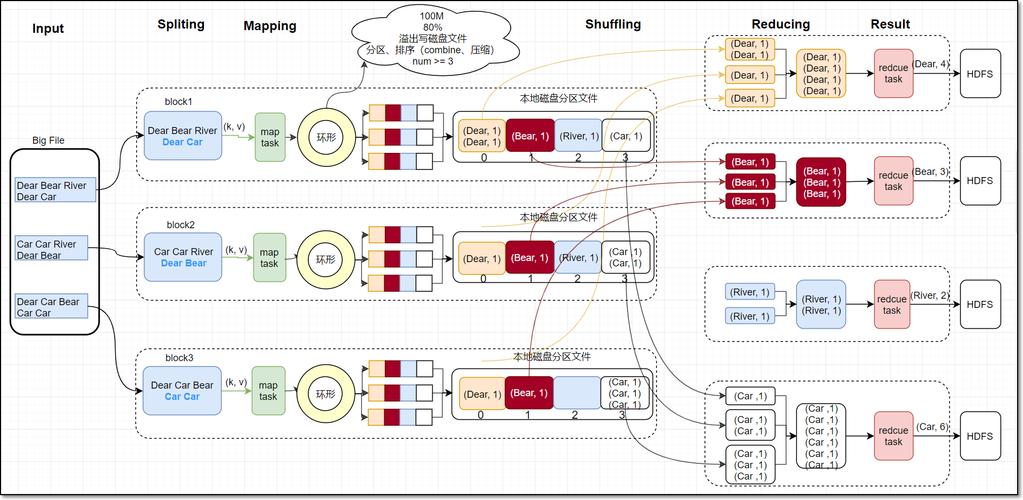
MapReduce 示例:单词计数
假设我们要统计一个大文本文件中各个单词出现的次数,下面是一个简化的MapReduce流程:
Map阶段
输入:文本文件分片
映射函数:读取每行文本,分割成单词,为每个单词生成一个(word, 1)对。
输出:每个Map任务生成一个局部的单词计数列表。
Shuffle阶段
数据传输:将Map任务产生的单词计数列表传输到Reduce任务。
全局排序:确保同一单词的计数会集中在一起。
Reduce阶段
输入:(word, [1,1,1,…])对
归约函数:对每个单词的出现次数求和。
输出:每个单词的总出现次数。
输出
输出:单词及其对应的总出现次数,通常写入到HDFS中。
相关问题与解答
Q1: MapReduce如何处理故障恢复?
A1: MapReduce框架设计有容错机制来处理节点故障,如果Map或Reduce任务失败,系统会自动重新调度该任务到其他节点上执行,Map任务的输出默认会写到本地磁盘,并且会在成功完成后被复制到Reduce任务所在节点,这样即使Map任务失败也不会丢失数据。
Q2: MapReduce是否适合处理实时数据处理?
A2: MapReduce本身是为批处理设计的,对于实时数据处理来说并不是最佳选择,它的设计目标是处理大量的静态数据,并且有一定的启动延迟,对于需要快速响应的实时数据分析,可以考虑使用如Apache Storm、Apache Flink或Apache Spark Streaming等流处理框架。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复