
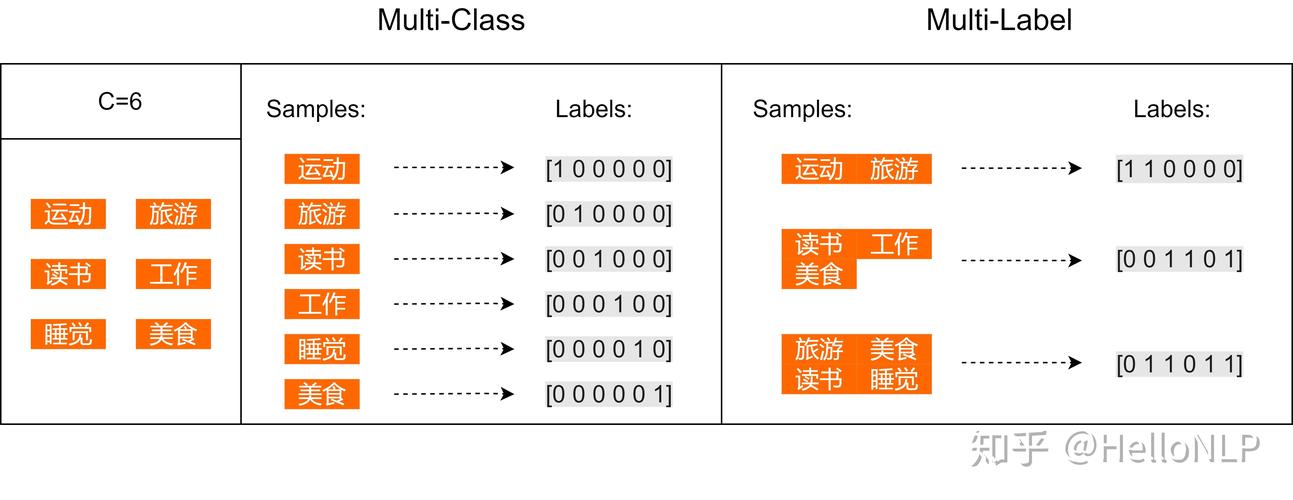
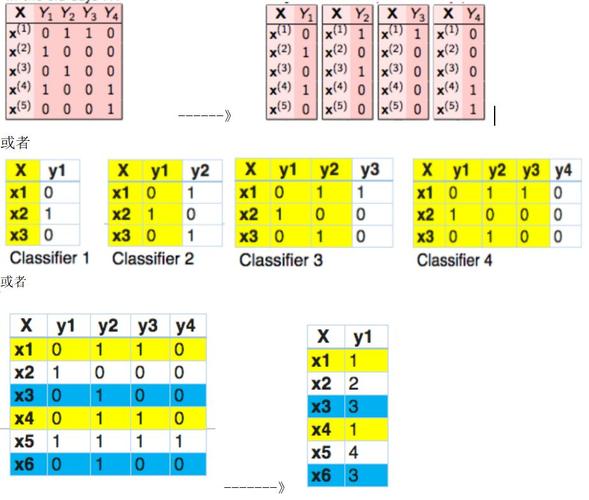
多标签分类问题是指在一个样本中可以同时属于多个类别,在MapReduce框架下,我们可以通过以下步骤实现多标签分类:

(图片来源网络,侵删)
1、数据预处理:将数据集划分为训练集和测试集,对数据进行清洗、去重等操作。
2、Map阶段:将训练集和测试集分别输入到Map函数中,对每个样本进行处理,对于训练集,提取每个样本的特征向量和对应的标签集合;对于测试集,提取每个样本的特征向量。
3、Shuffle阶段:将Map阶段的输出按照键值对进行排序和分组,使得具有相同键的键值对被分配到同一个Reduce任务中。
4、Reduce阶段:对每个键值对进行处理,将训练集中具有相同特征向量的样本合并,得到每个特征向量对应的标签集合,对于测试集,将具有相同特征向量的样本合并,得到每个特征向量对应的预测结果。
5、模型训练:使用训练集中的特征向量和对应的标签集合训练多标签分类模型,如线性支持向量机、随机森林等。
6、预测与评估:使用训练好的模型对测试集中的特征向量进行预测,得到每个样本的预测标签集合,计算预测结果与实际标签集合之间的准确率、召回率、F1值等评估指标。
以下是一个简单的MapReduce伪代码示例:
Map函数
def map(key, value):
# key: None
# value: 一行文本数据,格式为 "特征向量,标签1,标签2,..."
features, labels = value.split(',', 1)
labels = labels.split(',')
yield features, labels
Reduce函数
def reduce(key, values):
# key: 特征向量
# values: 包含多个标签集合的列表
all_labels = set()
for labels in values:
all_labels.update(labels)
yield key, all_labels 注意:以上代码仅为示例,实际应用中需要根据具体数据集和需求进行调整。
(图片来源网络,侵删)
(图片来源网络,侵删)
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复