
FastDFS 是一个开源的轻量级分布式文件系统,它对文件进行管理,功能包括:文件存储、文件同步、文件访问(文件上传、下载)等,解决了大量小文件存储问题,FastDFS 服务端是基于 C 语言开发的,具有高性能、高可用性等特点。

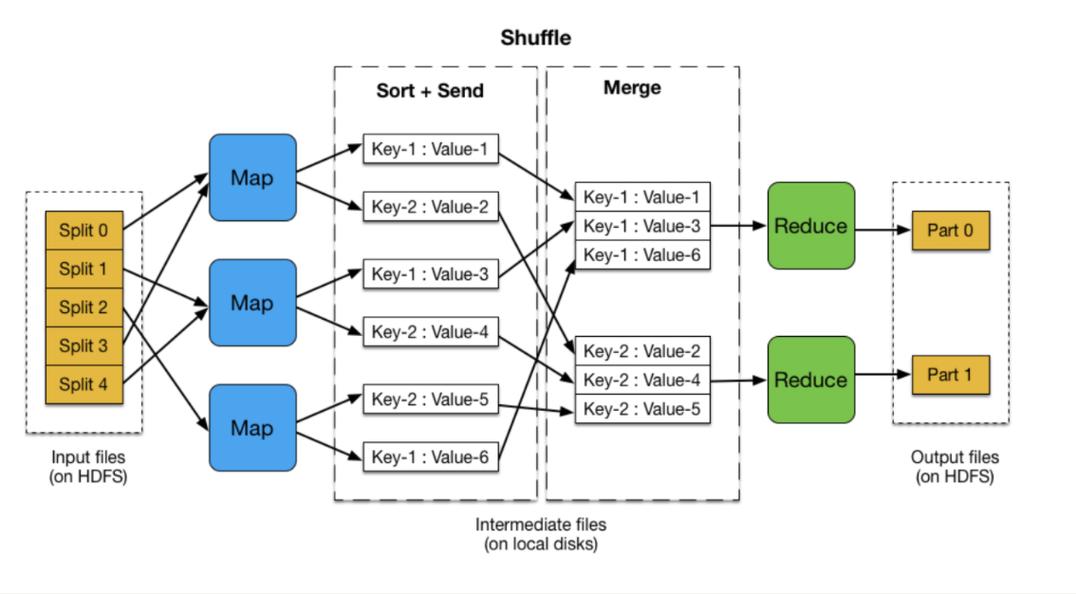
MapReduce 是一种编程模型和一个用于大规模数据集(大于1TB)并行运算的框架,概念"Map(映射)"和"Reduce(归约)",以及他们的主要思想,都是从函数式编程语言借来的,还有从矢量编程语言里借来的特性,这种编程模型特别适合于非结构化和结构化数据的处理,可以解决很多任务,特别是数据挖掘和分析领域的问题。
FastDFS MapReduce 是将 FastDFS 与 MapReduce 结合起来的一种应用,主要用于处理大规模文件系统中的数据,在 FastDFS MapReduce 中,Map 阶段主要是对文件系统中的文件进行处理,将文件内容转换为键值对;Reduce 阶段则是对这些键值对进行汇总和计算,得到最终结果。
下面是一个 FastDFS MapReduce 的示例:
导入所需库
from mrjob.job import MRJob
import fastdfs
class FastDFSMapReduce(MRJob):
def mapper(self, _, line):
# 连接 FastDFS 服务器
client = fastdfs.ConnectionPool('tracker_server=192.168.1.100')
# 从文件中读取数据
with open(line, 'r') as file:
data = file.read()
# 将数据转换为键值对
for word in data.split():
yield (word, 1)
def reducer(self, word, counts):
# 对键值对进行汇总和计算
yield None, sum(counts)
if __name__ == '__main__':
FastDFSMapReduce.run() 在这个示例中,我们首先导入了所需的库,然后定义了一个名为FastDFSMapReduce 的类,该类继承了MRJob,在mapper 方法中,我们连接到 FastDFS 服务器,并从文件中读取数据,我们将数据转换为键值对,其中键为单词,值为 1,在reducer 方法中,我们对键值对进行汇总和计算,得到每个单词的出现次数,我们运行这个任务。
通过 FastDFS MapReduce,我们可以在大规模文件系统中高效地处理数据,实现各种复杂的数据分析任务。
相关问题:
1、FastDFS MapReduce 中的 Map 阶段和 Reduce 阶段分别完成什么任务?
答:在 FastDFS MapReduce 中,Map 阶段主要负责对文件系统中的文件进行处理,将文件内容转换为键值对;Reduce 阶段则负责对这些键值对进行汇总和计算,得到最终结果。
2、FastDFS MapReduce 适用于哪些场景?
答:FastDFS MapReduce 适用于处理大规模文件系统中的数据,特别是在数据挖掘和分析领域,可以高效地实现各种复杂的数据分析任务。

【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复