
在分布式计算框架如Hadoop的MapReduce中,集成Kafka作为数据源是常见的需求,通过创建Kafka消费组,MapReduce作业能够消费Kafka中的消息数据进行处理,小编将详细介绍如何在MapReduce中消费Kafka并创建Kafka消费组。
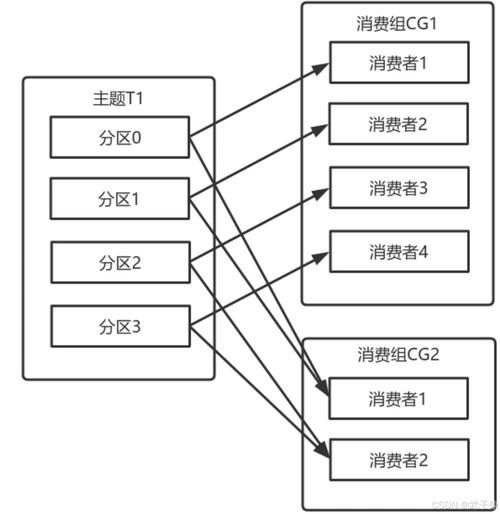

Kafka与MapReduce集成
1. Kafka简介
Kafka是一个分布式的发布订阅消息系统,它主要用于处理实时数据流,Kafka的设计允许高吞吐量、可扩展和高可用性,使其成为大数据处理的理想选择。
2. MapReduce简介
MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。“映射”(Map)和“归约”(Reduce)是该模型的主要步骤。
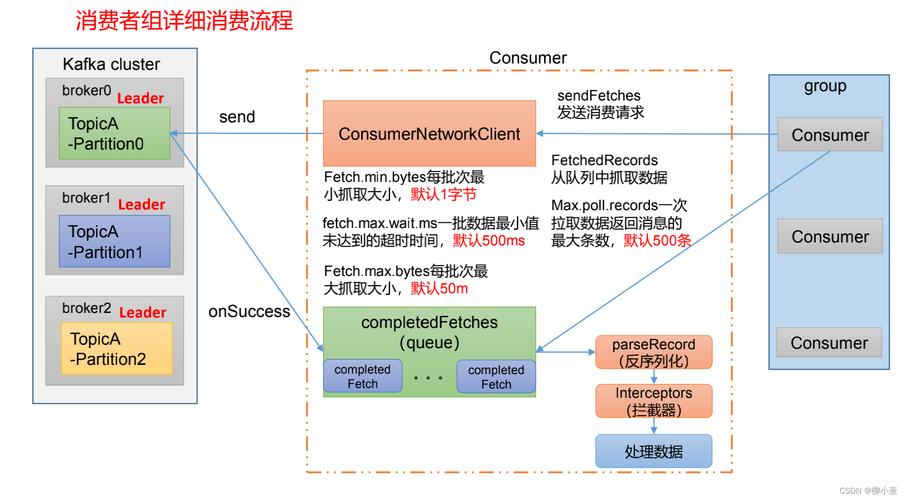
Kafka消费组的创建和配置
1. 环境准备
首先确保你的Hadoop集群已经搭建好,并且Kafka也已经安装配置完成,需要有对Kafka和Hadoop操作的基本知识。
2. 创建Kafka消费者
在MapReduce中消费Kafka,需要创建一个Kafka消费者来连接到Kafka集群并读取消息。
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("group.id", "mapreduceconsumergroup");
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props); 3. 订阅主题
消费者需要订阅特定的Kafka主题以便接收消息。
consumer.subscribe(Arrays.asList("mytopic")); 4. 集成到MapReduce作业中
在MapReduce作业中,通常在Mapper中进行Kafka的消费操作,需要在驱动类中配置相应的输入格式和相关参数。
job.setInputFormatClass(KafkaInputFormat.class); KafkaInputFormat.setConsumerKeyDeserializerClass(job, StringDeserializer.class); KafkaInputFormat.setConsumerValueDeserializerClass(job, StringDeserializer.class); KafkaInputFormat.setConsumerProps(job, props);
相关问题与解答
Q1: Kafka消费组中的消费者如何实现负载均衡?
A1: Kafka消费组内的多个消费者可以通过协调者(Coordinator)实现负载均衡,每个分区只能由消费组内的一个消费者消费,协调者负责分配分区给消费组内的消费者,如果某个消费者失效,协调者会将失效消费者的分区重新分配给其他消费者。
Q2: 在MapReduce中使用Kafka作为数据源有哪些优势?
A2: 使用Kafka作为MapReduce的数据源可以带来以下优势:
实时处理能力:Kafka提供实时数据流,MapReduce可以处理这些实时数据,满足实时分析的需求。
高吞吐量:Kafka的高吞吐量特性使得MapReduce可以高速地从Kafka消费大量数据。
容错性:Kafka的副本机制和消费组的重新平衡机制提供了高容错性,保证数据处理的稳定性。
解耦数据生成和数据处理:生产者和消费者可以独立扩展和演化,提高了系统的灵活性和可维护性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复