
Kafka作为大数据处理中广泛使用的分布式流处理平台,其数据备份和元数据管理对于保障系统的稳定性和数据的可靠性至关重要,下面将详细介绍如何进行Kafka元数据的备份以及相关机制。

一、Kafka的数据备份类型
Kafka支持全量备份和增量备份两种策略,以满足不同场景下的数据安全需求:
1、全量备份
定义与实现:全量备份涉及将Kafka中的所有数据复制到另一个位置,通常是另一个存储设备或系统,这种方式确保了数据的完整性,但可能消耗更多的时间和资源。
适用场景:适合于周期性的大规模数据保护,如每周或每月执行一次全量备份来确保数据的全面性。
操作方法:可通过命令行工具执行备份指令,指定要备份的主题和目标备份目录。
2、增量备份
定义与实现:在完成全量备份的基础上,仅备份自上次全量备份以来发生变更的数据,这种备份方式较为高效,可减少备份所需的时间和空间。
适用场景:适合于数据变化频繁的环境,可以在短时间内恢复数据至最新状态。
操作方法:同样可以使用Kafka提供的工具进行操作,需要配置从特定起始点开始备份数据。
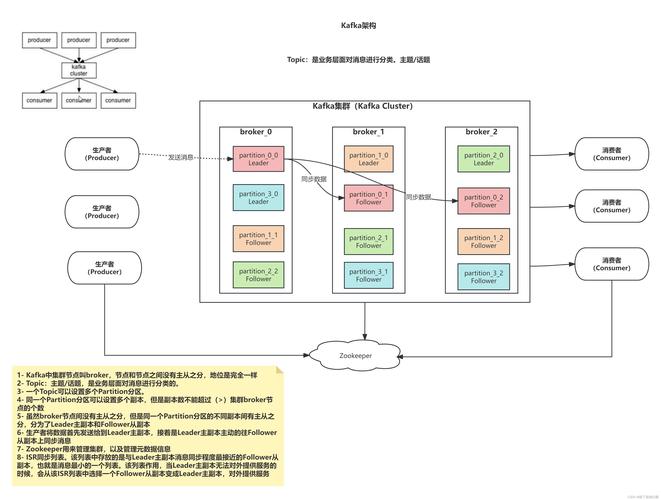
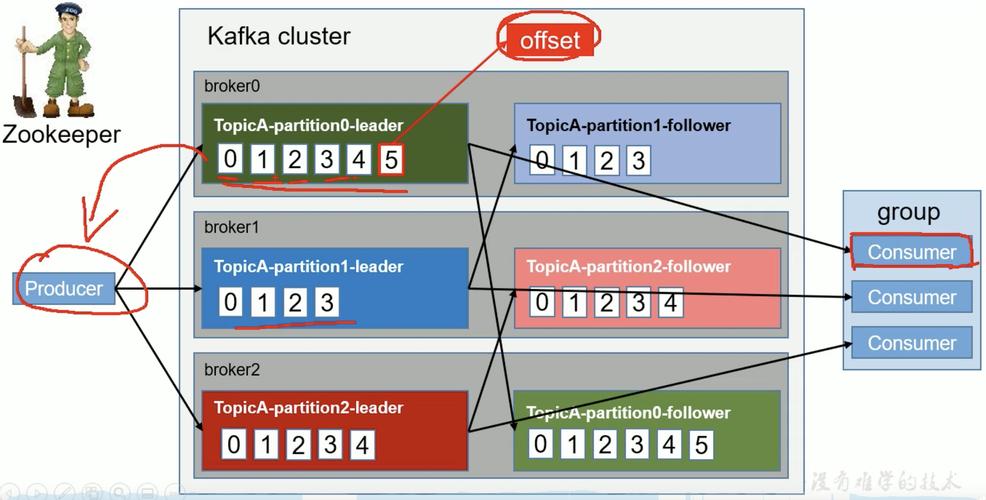
二、Kafka的副本机制
Apache Kafka采用副本机制来提高数据的可用性和容错能力:
1、副本与分区
基本概念:主题被划分为多个分区,每个分区拥有一个或多个副本,每个副本分别部署在不同的服务器上,以提升系统的容错性。
角色分配:分区中的副本分为领导者副本和追随者副本,领导者副本负责处理所有写入请求,而追随者副本从领导者副本同步数据。
2、同步机制
ISR集合:ISR集合是指与领导者副本保持数据一致性的追随者副本集合,只有处于ISR集合中的副本才被认为是健康的并且能够接管领导者角色。
故障转移:如果领导者副本出现故障,Kafka会从ISR集合中选举新的领导者副本,以确保分区继续提供服务。
3、副本同步
同步过程:追随者副本通过从领导者副本拉取消息来同步数据,此过程确保了即使部分副本发生故障,数据也不会丢失。
延迟问题:虽然副本机制提高了系统的可靠性,但也可能会引入数据同步的延迟,设计时需要考虑副本的数量和分布以平衡性能和可靠性。
三、管理Kafka元数据
Kafka的元数据由Zookeeper管理,这包括主题、分区、副本及位置信息等:
1、元数据结构
角色定位:Zookeeper帮助维护活动的Broker列表,并存储有关主题和分区的元数据信息。
重要性:正确的元数据管理对Kafka的性能和正常运行至关重要,因为元数据描述了数据的位置及其在系统中的流向。
2、元数据同步
同步机制:当新的消息被写入或读取时,Zookeeper会更新相应的元数据信息,确保所有参与者都能看到一致的数据状态。
影响分析:元数据的不一致性可能导致消息丢失或错误路由,因此保证元数据的准确和及时更新是关键。
四、备份Kafka任务的创建与管理
系统管理员可以通过特定的工具或平台创建和管理备份Kafka的任务:
1、任务创建
自动化与手动:支持自动或手动创建备份任务,根据实际需求和资源情况选择适合的方式。
工具支持:例如FusionInsight Manager等工具提供了用户友好的界面来配置和管理备份任务。
2、监控与恢复
任务监控:定期检查备份任务的状态,确保备份活动正常进行且无错误发生。
数据恢复:在数据丢失或损坏时,可以利用备份数据进行快速恢复,最小化损失。
五、常见问题解答
以下是一些常见的问题及其解答,旨在进一步澄清关于备份Kafka元数据的疑问:
1、Q1:全量备份和增量备份有何区别?
A1:全量备份指备份所有数据,适用于基础备份;而增量备份仅备份自上次全量备份以来的新增数据,适用于日常的数据保护。
2、Q2:Kafka如何通过副本机制保证数据不丢失?
A2:通过为每个分区配置多个副本并在ISR集合中维护同步的追随者副本,即使领导者副本出现问题,也能通过追随者副本接管并继续服务,从而防止数据丢失。
备份Kafka元数据是一项关键的任务,确保了在系统故障或数据损坏时能迅速恢复服务,通过合理配置和使用现有的备份和副本机制,可以显著提高Kafka的可靠性和数据的安全性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复