
倒排索引是一种用于全文搜索和信息检索的数据结构,它将文档中的每个单词映射到一个包含该单词的所有文档的列表中,MapReduce是一种分布式计算框架,可以用于处理大量数据。
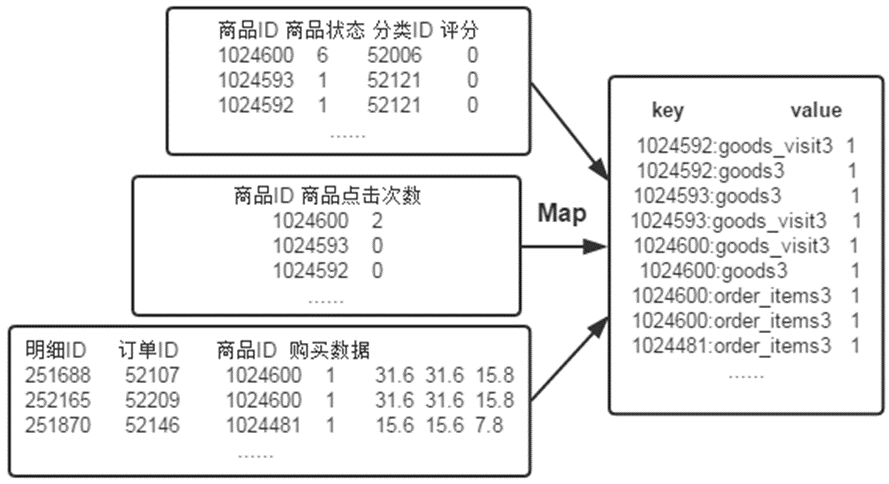

在MapReduce中,倒排索引可以通过以下步骤实现:
1、映射阶段(Map):将输入的文本文件拆分成单词,并为每个单词生成一个键值对,键为单词,值为该单词所在的文档ID。
2、洗牌阶段(Shuffle):将相同单词的键值对按键进行排序,并将它们发送到同一个Reduce任务。
3、归约阶段(Reduce):对于每个单词,将所有的文档ID合并成一个列表,并输出该单词和对应的文档列表。
下面是一个使用Python编写的简单示例代码,演示了如何在MapReduce中实现倒排索引:
导入所需的库
from mrjob.job import MRJob
from mrjob.step import MRStep
import re
定义Mapper类
class TokenizerMapper(MRJob):
def mapper(self, _, line):
# 将输入行拆分成单词,并去除标点符号和停用词
words = re.findall(r'w+', line.lower())
for word in words:
yield word.strip(), line.split()[0] # 输出单词和文档ID
定义Reducer类
class InvertedIndexReducer(MRJob):
def reducer(self, word, values):
# 将相同单词的值合并成一个列表,并输出该单词和对应的文档列表
yield word, list(set(values))
主函数,运行MapReduce任务
if __name__ == '__main__':
TokenizerMapper.run()
InvertedIndexReducer.run() 代码实现了一个简单的倒排索引MapReduce任务,Mapper类将输入的文本文件拆分成单词,并为每个单词生成一个键值对,键为单词,值为该单词所在的文档ID,Reducer类将相同单词的值合并成一个列表,并输出该单词和对应的文档列表,通过运行TokenizerMapper.run()和InvertedIndexReducer.run()来执行整个MapReduce任务。
相关问题与解答:
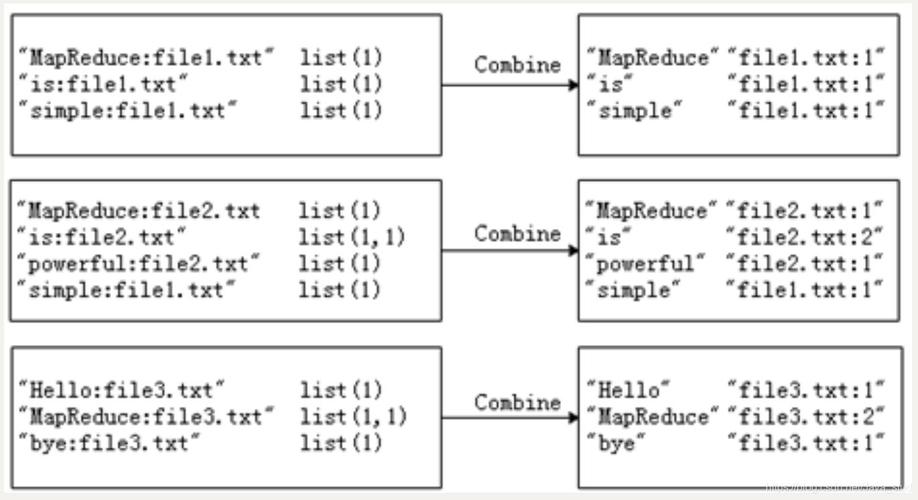
1、MapReduce是什么?如何理解MapReduce的工作原理?
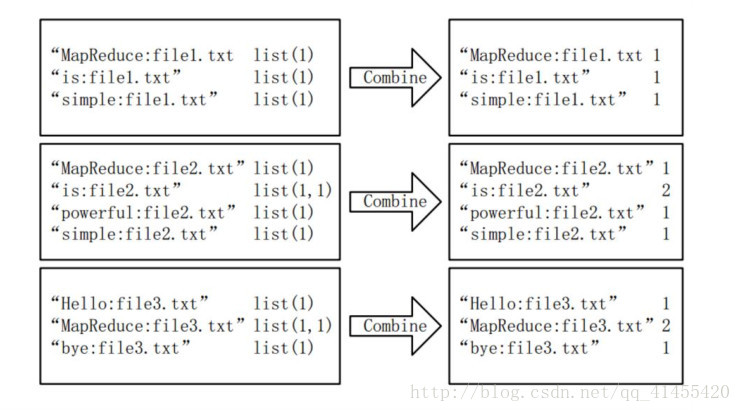
MapReduce是一种分布式计算框架,用于处理大量数据,它由两个主要阶段组成:映射阶段(Map)和归约阶段(Reduce),在映射阶段,输入数据被拆分成多个小任务,并由不同的节点并行处理,每个节点负责处理一部分数据,并将结果传递给下一个阶段的Reduce节点,在归约阶段,Reduce节点接收来自所有映射节点的结果,并根据指定的归约函数对这些结果进行处理和合并,MapReduce将产生一个或多个最终结果。
MapReduce的工作原理基于分而治之的思想,通过将大规模数据集拆分成多个小任务并行处理,可以提高数据处理的效率和速度,MapReduce还提供了容错机制和自动并行化的能力,使得开发者可以专注于数据的处理逻辑,而无需关注分布式计算的细节。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复