
在当今大数据和人工智能时代,数据流处理和分析变得尤为重要,MapReduce 是一种编程模型,用于处理大规模数据集,而 Kafka 是一个分布式流处理平台,常用于构建实时的数据处理应用程序,本文将介绍如何将 MapReduce 作业的输出导入到 Kafka,并最终导出到 AI Gallery 进行进一步的数据分析或展示。

MapReduce 基础
MapReduce 是 Google 提出的一种编程模型,旨在简化大数据集的处理,它包括两个主要阶段:Map 和 Reduce。
Map 阶段:此阶段对输入数据进行分割,并在多个节点上并行处理,生成中间键值对。
Reduce 阶段:此阶段接收 Map 阶段的输出,根据键来聚合值,并生成最终结果。
Kafka简介
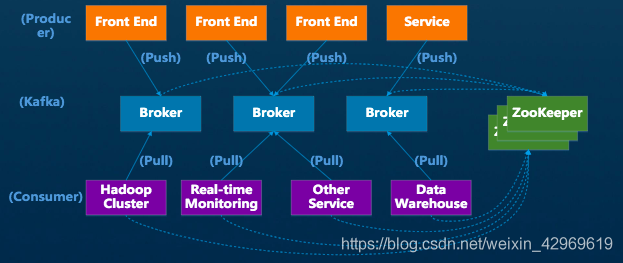
Apache Kafka 是一个分布式流处理平台,它支持高吞吐量、可容错的发布和订阅消息传递,Kafka 的核心概念包括:
Topic:消息的类别或 feed 名称。
Producer:发布消息到 Topic。
Consumer:订阅 Topic 并处理消息。
MapReduce 输出到 Kafka
要将 MapReduce 作业的输出发送到 Kafka,需要以下几个步骤:
1、配置 Kafka Producer:在你的 MapReduce 应用中设置 Kafka Producer,指定 Broker 列表和 Topic。
2、编写 MapReduce 作业:修改 Reduce 阶段的代码,使其输出格式为 Kafka 所需的消息格式。
3、集成 Kafka Producer:在 Reduce 阶段结束后,使用 Kafka Producer 将数据发送到指定的 Kafka Topic。
示例代码
// 创建 Kafka Producer
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
// 在 MapReduce 的 Reduce 阶段后发送消息到 Kafka
public void reduce(Object key, Iterable<Object> values, Context context) throws IOException, InterruptedException {
// ... 你的 reduce 逻辑
String result = // 你的处理结果;
producer.send(new ProducerRecord<String, String>("your_topic", key.toString(), result));
} 导出到 AI Gallery
一旦数据被发送到 Kafka,可以由其他服务消费这些数据并将其导出到 AI Gallery,AI Gallery 通常指的是一个平台,用于展示和管理 AI 模型和相关数据,为了将数据从 Kafka 导出到 AI Gallery,你可能需要开发一个自定义的 Kafka Consumer 应用,该应用读取 Kafka Topic 中的数据,并将其上传到 AI Gallery。
相关问题与解答
Q1: Kafka Producer 在 MapReduce 作业中的性能影响是什么?
A1: Kafka Producer 在 MapReduce 作业中的集成可能会增加作业的运行时间,因为生产者需要序列化消息并将它们发送到 Kafka Broker,这可能导致额外的网络开销和延迟,优化生产者的配置(如批量大小和缓冲机制)可以帮助减少这种影响。
Q2: Kafka Broker 不可用怎么办?
A2: Kafka Broker 暂时不可用,MapReduce 作业可能会因无法发送消息而失败,为了避免这种情况,可以在代码中实现重试逻辑,或者配置 Kafka Producer 的retries 和retry.backoff.ms 参数来自动重试,确保 Kafka Broker 的高可用性和监控也是关键。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复