
在当今大数据时代,MapReduce作为一种数据处理模型,广泛应用于分布式系统,尤其是基于Hadoop框架的应用,对于开发者来说,能够有效利用Eclipse这一集成开发环境(IDE)来开发和运行MapReduce程序,无疑能极大提高开发效率和便捷性,接下来将深入探讨在Eclipse环境下如何开发和运行MapReduce应用程序的详细流程。
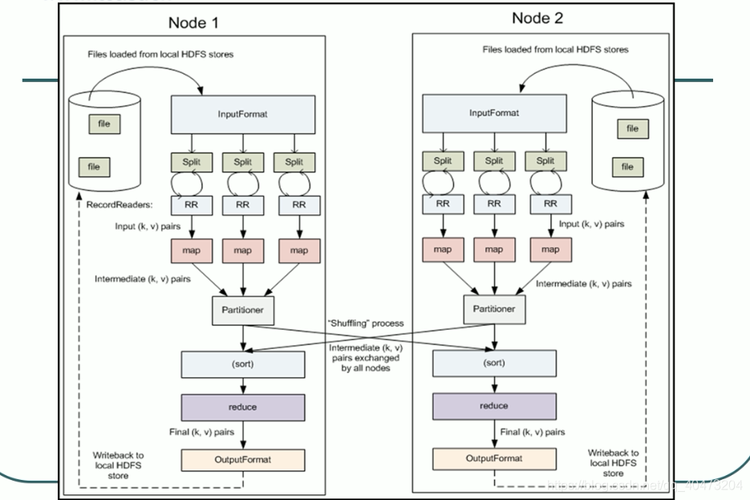

环境配置
确保开发环境的正确设置是成功开发和运行MapReduce程序的第一步,安装有Eclipse IDE的操作系统(如Ubuntu/CentOS或Windows)是基础要求,需要安装与Hadoop版本兼容的Java开发工具包(JDK),因为MapReduce应用是用Java编写的,具体到Windows环境,还需安装hadoopEclipsePlugin来方便Eclipse与Hadoop的集成。
创建MapReduce项目
在Eclipse中创建一个新项目,并选择MapReduce项目模板,这一步骤为后续的开发工作奠定了基础,使开发者可以直接进入到编写代码的阶段。
编写MapReduce程序
1、Mapper类的实现:
继承Mapper类,并重写map方法来实现对输入数据的分析。
在map方法中,通过context对象收集键值对输出。
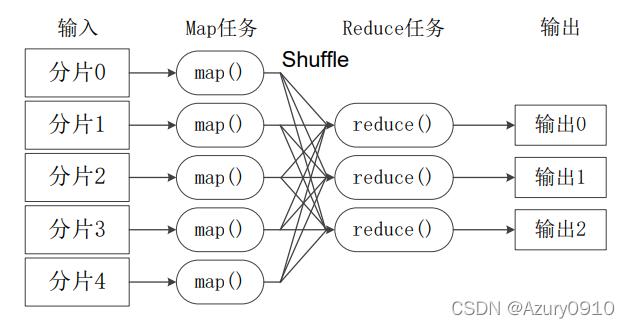
2、Reducer类的实现:
继承Reducer类,并重写reduce方法来处理Mapper的输出。
在reduce方法内,实现对具有相同键的值的处理逻辑。
3、Driver类的编写:
配置作业运行参数,如输入输出路径、作业名称等。
设置Mapper和Reducer类。
通过Job对象的waitForCompletion方法启动作业。
配置Hadoop环境
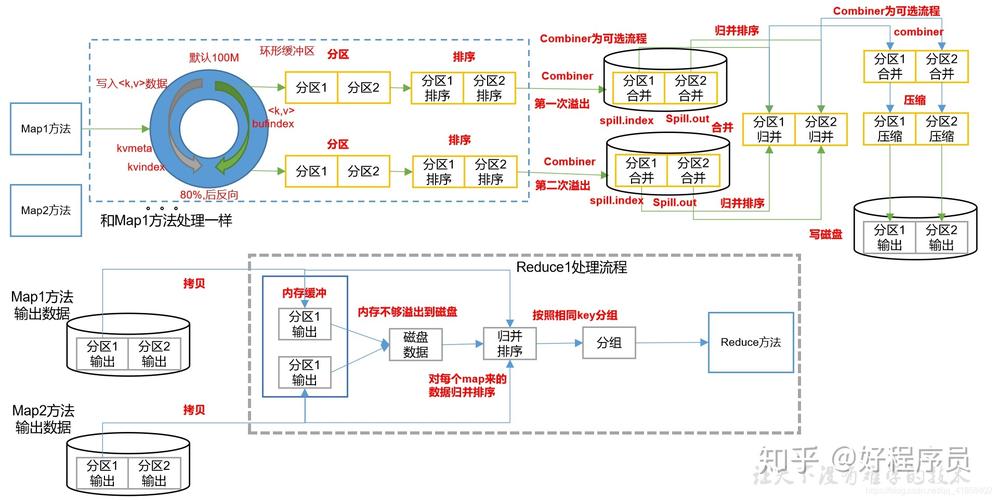
1、Hadoop集群配置:
确保Hadoop集群正确安装并运行。
配置mapredsite.xml和coresite.xml文件,设置Hadoop相关参数。
2、环境变量设置:
在系统的环境变量中添加JAVA_HOME和HADOOP_HOME,指向正确的JDK和Hadoop安装目录。
运行和调试
在Eclipse中,右键点击项目名,选择“Run As” > “Hadoop MapReduce Job”。
使用Eclipse的调试功能进行断点设置,监控程序执行过程,方便查找和修正bugs。
结果验证与优化
检查Hadoop集群上作业的运行状态和输出结果。
根据实际运行情况调整MapReduce程序的性能,如调整内存配置、优化数据读写等。
通过以上步骤,可以在Eclipse环境下高效地开发和运行MapReduce应用程序,每个环节都有其重要性和细节,开发者需根据实际情况进行调整和优化。
将探讨一些常见问题及其解决策略,以帮助更好地理解和应用上述流程。
相关问题与解答
Q1: 如何解决Eclipse中无法找到Hadoop类的问题?
A1: 确保Eclipse安装了hadoopEclipsePlugin插件,并且在项目的构建路径中添加了Hadoop的jar包,检查环境变量中HADOOP_HOME是否指向了正确的Hadoop安装目录。
Q2: 运行MapReduce程序时遇到性能瓶颈该如何优化?
A2: 可以从以下几个方面进行优化:
代码层面:优化数据结构,减少不必要的数据操作。
Hadoop配置:调整map和reduce任务的数量,优化集群资源分配。
硬件层面:增加集群节点,提升计算能力和存储容量。
通过Eclipse开发和运行MapReduce程序不仅提高了开发效率,还使得调试和维护变得更加方便,希望本文能够帮助读者在实际应用中更加顺利地进行MapReduce应用的开发和优化。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复