
【EMapReduce】

EMapReduce是一种基于云计算的分布式计算框架,它允许用户在云平台上进行大规模数据处理和分析,通过使用EMapReduce,用户可以将大规模的数据集分割成多个小任务,并在多个计算节点上并行执行这些任务,从而提高数据处理的效率和速度。
EMapReduce的特点
1、弹性扩展:EMapReduce可以根据用户的需求自动调整计算资源的规模,从而满足不同规模的数据处理需求。
2、高可靠性:EMapReduce采用分布式存储和计算的方式,可以保证数据的可靠性和容错性。
3、易用性:EMapReduce提供了丰富的API和工具,使得用户可以方便地编写和提交MapReduce作业。
4、高性能:EMapReduce采用了多种优化技术,如数据本地化、任务调度优化等,以提高数据处理的性能。
EMapReduce的架构
EMapReduce的架构主要包括以下几个部分:
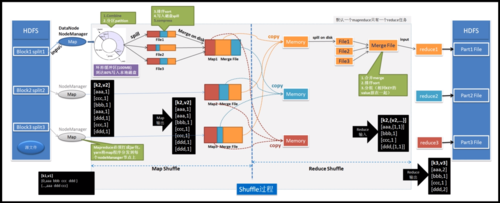
1、用户界面:用户可以通过Web界面或者命令行工具提交MapReduce作业。
2、调度器:调度器负责根据作业的要求和集群的资源情况,将作业分解成多个任务并分配给计算节点。
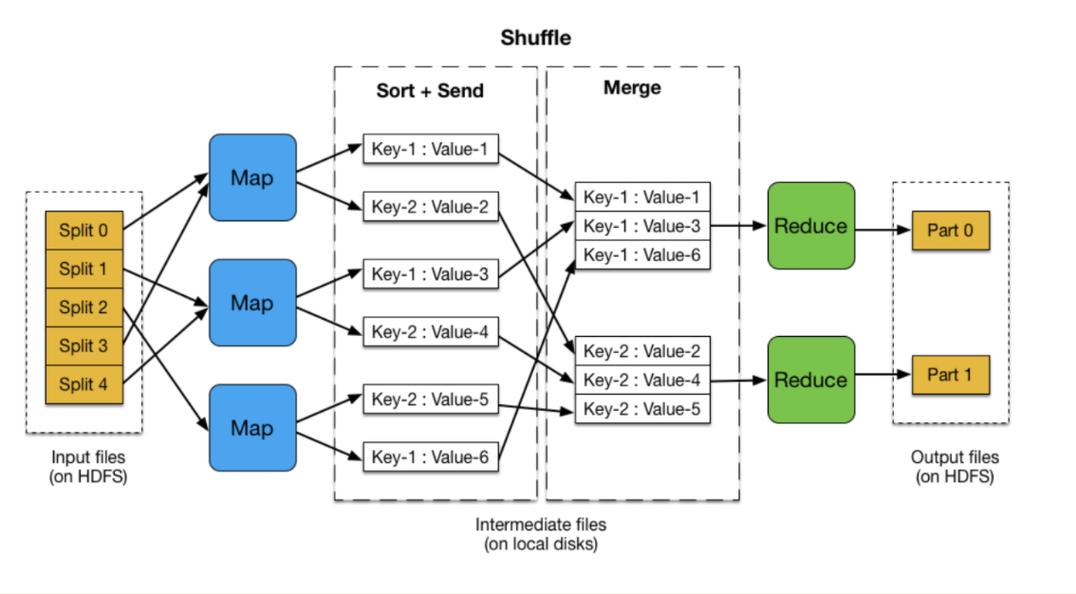
3、集群管理器:集群管理器负责管理集群中的计算节点,包括节点的添加、删除、状态监控等。
4、任务执行器:任务执行器负责在计算节点上执行具体的MapReduce任务。
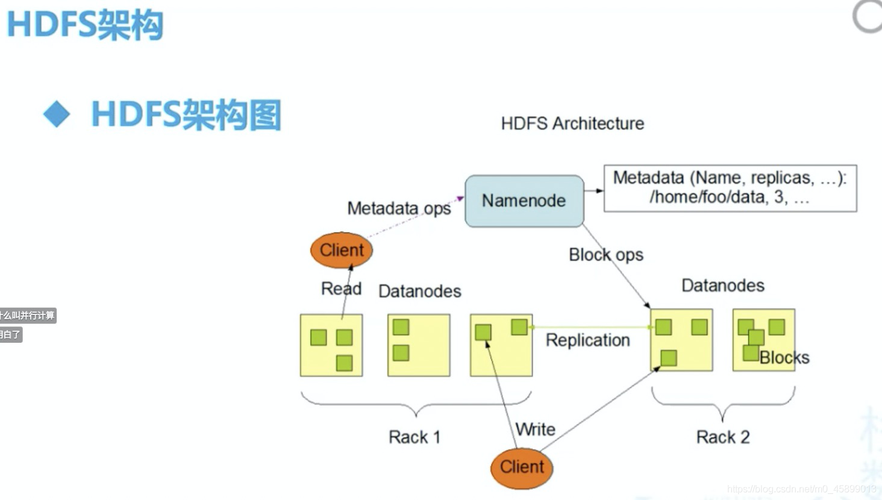
5、分布式文件系统:分布式文件系统负责存储和管理用户的数据和作业结果。
EMapReduce的使用流程
使用EMapReduce的基本流程如下:
1、编写MapReduce程序:用户需要编写一个MapReduce程序,该程序包括一个Mapper函数和一个Reducer函数。
2、提交MapReduce作业:用户通过Web界面或者命令行工具提交MapReduce作业。
3、作业调度和执行:调度器根据作业的要求和集群的资源情况,将作业分解成多个任务并分配给计算节点,任务执行器在计算节点上执行具体的MapReduce任务。
4、查看作业结果:作业完成后,用户可以查看作业的结果。
EMapReduce的应用场景
EMapReduce适用于以下几种场景:
1、大数据分析:EMapReduce可以处理大规模的数据集,适合用于大数据分析。
2、日志处理:EMapReduce可以处理大量的日志数据,适合用于日志分析和处理。
3、数据清洗:EMapReduce可以对数据进行清洗和转换,适合用于数据预处理。
4、机器学习:EMapReduce可以用于机器学习算法的训练和预测。
与本文相关的问题及解答
问题1:EMapReduce和Hadoop MapReduce有什么区别?
答:EMapReduce是基于云计算的分布式计算框架,而Hadoop MapReduce是Hadoop项目中的一个子项目,是一个开源的分布式计算框架,两者的主要区别在于运行环境,EMapReduce运行在云平台上,而Hadoop MapReduce运行在用户的私有数据中心中,EMapReduce提供了更丰富的API和工具,使得用户可以更方便地使用和管理MapReduce作业。
问题2:如何提高EMapReduce的数据处理性能?
答:提高EMapReduce的数据处理性能可以从以下几个方面入手:可以通过调整作业的规模来提高数据处理的速度;可以通过优化任务调度策略来减少任务的等待时间;可以通过使用更高效的算法来提高数据处理的效率。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复