
分布式计算存储平台利用分布式存储来处理和存放大规模数据集,通过在多台计算机或服务器上分散数据来提高可靠性、可扩展性和性能,下面将深入探讨数据分布式存储的各个方面:
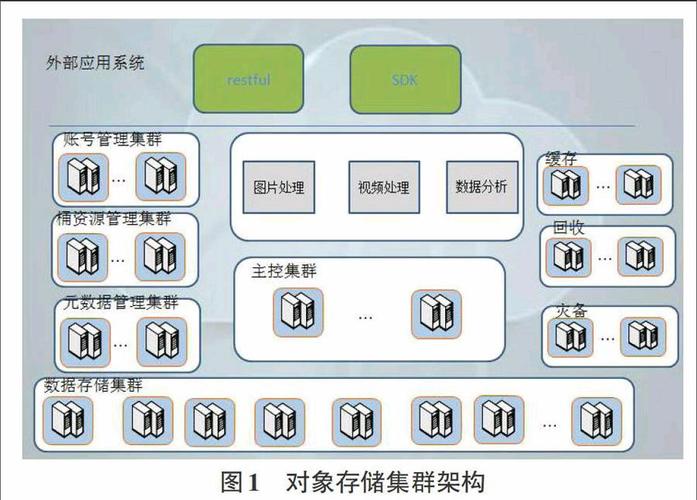

1、分布式文件系统的基础架构
GFS和HDFS:Google文件系统(GFS)是分布式文件系统的一种实现方式,而Hadoop Distributed File System (HDFS) 是基于GFS的思想开发的开源实现,它们都将数据存储为分布在多个节点的块,通过主节点(Master)和多个从节点(Slave)的架构进行管理。
数据分块与冗余:大文件被分割成多个数据块(block),每个数据块在系统中多个节点上有副本,以保证数据的可靠性和可用性。
元数据管理:主节点负责管理元数据,即文件到数据块的映射信息,以及数据块的位置信息,而从节点则实际存储数据块。
容错机制:分布式文件系统通常包括故障检测和自动恢复的机制,以确保数据不丢失,并能在节点故障后继续提供服务。
2、分布式存储的设计理念
高可靠性:多副本和故障转移策略确保了数据的高可靠性,即使硬件发生故障,也不会导致数据丢失。
可扩展性:分布式存储系统支持动态添加存储节点,以应对数据量的增长,保持系统的平衡和高效。
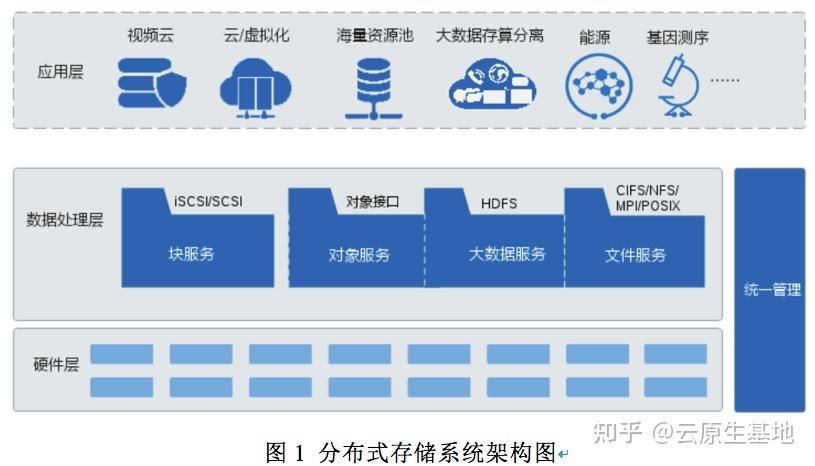
高性能:通过网络传输的优化和数据的并行处理,分布式存储系统能够提供高性能的数据访问能力。
3、关键技术与算法
数据一致性:分布式存储系统需要保证数据的强一致性或最终一致性,采用如Paxos、Raft等分布式一致性算法确保数据在不同节点间的一致性。
数据分片与复制:合理的数据分片(Sharding)和复制策略能够提高系统的吞吐量和容错能力。
负载均衡:系统应能根据各节点的实时负载情况进行任务调度,实现负载均衡,避免单个节点成为性能瓶颈。
4、分布式存储的实现方式
单机存储对比:与传统的单机存储不同,分布式存储通过网络连接众多节点,形成了一个逻辑上的整体,可以存储和管理远超单机容量的数据。
存储节点的作用:每个节点既可以作为存储数据的从节点,又可以承担计算任务,实现存储与计算的一体化。
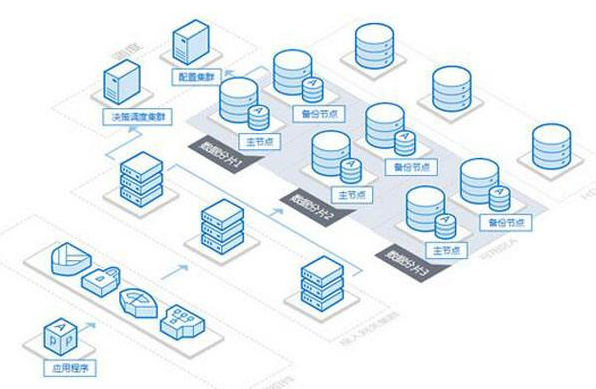
文件系统接口:分布式文件系统提供与本地文件系统相似的接口,使得上层应用无需关心底层的分布式细节。
5、分布式存储的使用场景
大数据处理:适用于需存储和分析大型数据集的场景,如互联网日志分析、商业智能等。
云存储服务:云服务提供商常用分布式存储为用户供给数据存储、备份和共享服务。
科学计算:大规模科学计算产生的数据也常使用分布式存储,以便进行高效的数据处理和分析。
6、实际案例与系统实例
Google的GFS:作为分布式文件系统的典型实例,GFS对后续的分布式存储系统设计产生了深远影响。
Apache Hadoop:作为最著名的大数据处理平台之一,其HDFS是分布式存储在实践中广泛应用的案例。
云服务平台:如Amazon S3、Microsoft Azure Blob Storage等,都是基于分布式存储原理构建的服务。
7、分布式存储的优势与挑战
优势:提供几乎无限的数据存储能力、高并发访问支持以及良好的系统扩展性。
挑战:包括数据一致性维护、系统安全性、网络延迟和带宽限制等问题。
转向更深入的方向,了解分布式存储系统的实际部署和使用考量,以及未来的发展预期,可以帮助人们更全面地理解这一概念:
部署成本:考虑分布式存储系统的硬件、软件及运维成本,评估总体投资和回报。
系统兼容性:考虑如何将新的分布式存储系统与现有的IT基础设施和业务流程整合。
安全性问题:数据加密、访问控制和防止各类网络攻击是设计和使用分布式存储系统时必须考虑的问题。
技术发展趋势:随着技术的演进,分布式存储领域可能会出现新的技术创新和突破。
可以看到分布式存储不仅是大数据时代的产物,也是推动信息技术进步的关键力量,从Google的GFS到Apache Hadoop,再到各种云平台上的实现,分布式存储正成为处理海量数据集不可或缺的基础设施,它通过对数据的分块、复制和分布存储,实现了存储空间的线性扩展和数据可靠性的大幅提升。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复