
MapReduce是一种编程模型,用于处理和生成大数据集,它是由谷歌在2004年提出的,并迅速成为大数据处理的一个关键技术,MapReduce的核心思想是将复杂的数据处理任务分解为两个阶段:Map阶段和Reduce阶段。
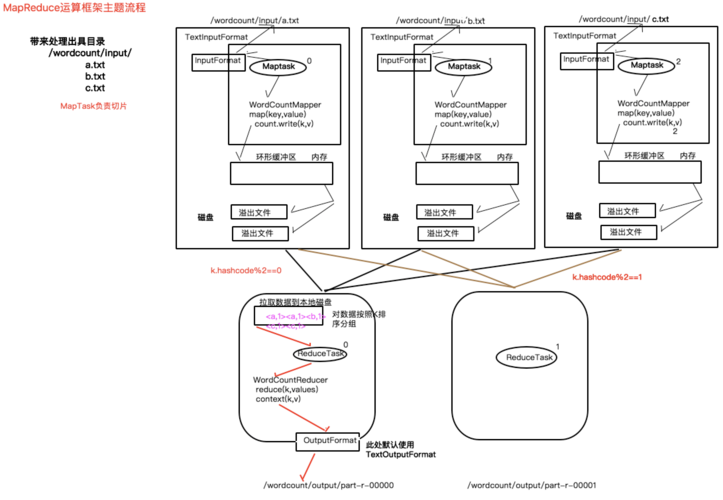

Map阶段
在Map阶段,输入数据被拆分成多个小数据块,每个数据块由一个Map任务独立处理,这些任务通常运行在不同的机器上以实现并行处理,每个Map任务会处理其分配的数据块,并将结果输出为一组键值对,如果我们想要统计大量文本中单词的出现次数,Map任务可能会输出如下键值对:(word, 1)。
Shuffle阶段
Shuffle阶段是MapReduce框架自动进行的,它负责将Map阶段的输出根据键值进行排序和分组,使得具有相同键的所有值都发送到同一个Reduce任务,这个阶段对于用户来说是透明的,但它是确保数据正确聚合的关键步骤。
Reduce阶段
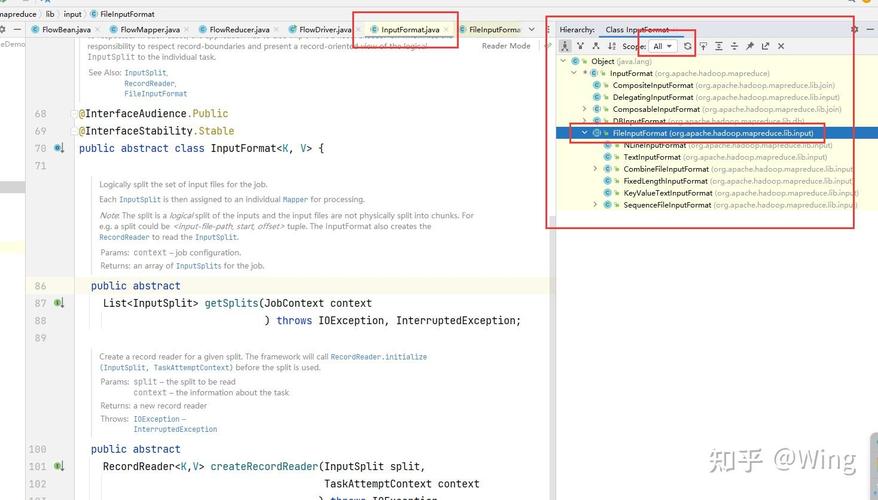
在Reduce阶段,每个Reduce任务接收到一组特定键的所有值,然后对这些值进行处理以生成最终的结果,继续上面的例子,Reduce任务可能会将所有相同的单词出现次数相加,得到每个单词的总出现次数。
MapReduce的优势
可扩展性:通过增加更多的节点来处理更大的数据集。
容错性:单个节点失败不会导致整个作业失败,因为工作可以在其他节点上重新执行。
简单性:程序员只需关注Map和Reduce函数的实现,无需担心并行化和分布式处理的细节。
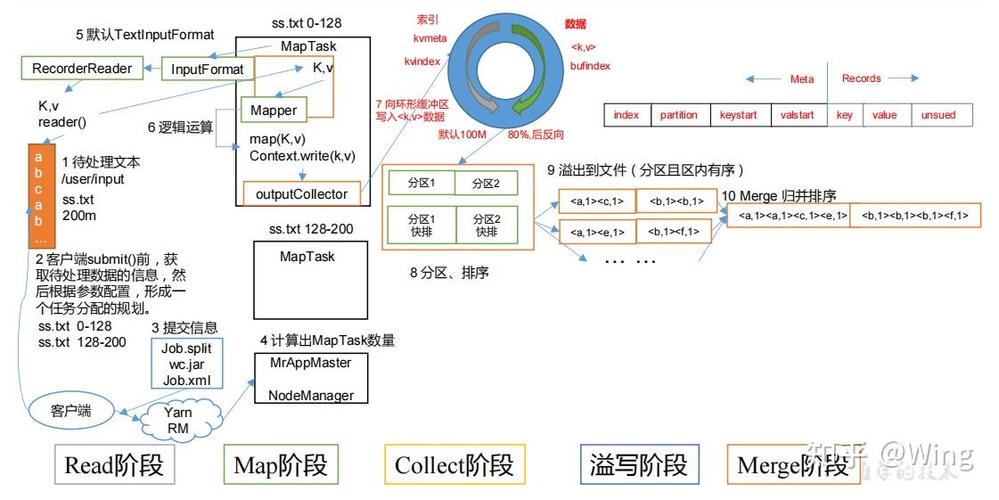
MapReduce的限制
实时处理:由于设计用于批处理,不适合需要快速响应的实时计算场景。
迭代算法:对于需要频繁读写中间结果的迭代算法效率不高。
资源利用:在某些情况下可能无法充分利用所有节点的资源。
应用场景
MapReduce适用于多种数据处理任务,如日志分析、文档聚类、基于统计的机器翻译等。
相关问题与解答
Q1: MapReduce如何处理大规模数据集?
A1: MapReduce通过将数据集分成多个小块,每个块由不同的Map任务独立处理,从而实现了大规模数据集的并行处理,之后,通过Shuffle阶段将Map的输出按照键值进行分组,最后由Reduce任务处理这些分组数据以产生最终结果。
Q2: MapReduce适合哪些类型的计算任务?
A2: MapReduce最适合于那些可以分解为独立的子任务,并且这些子任务之间不需要频繁通信的任务,典型的应用场景包括数据的批量处理、计数、排序、分组等,对于那些需要频繁迭代和通信的任务,或者对响应时间有严格要求的应用,MapReduce可能不是最佳选择。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复