
Kafka 是由Apache Software Foundation管理的高性能、可扩展的分布式消息服务,它主要用于处理实时数据流和大规模消息传递,下面将详细介绍Kafka的核心特性、基础概念以及应用场景:
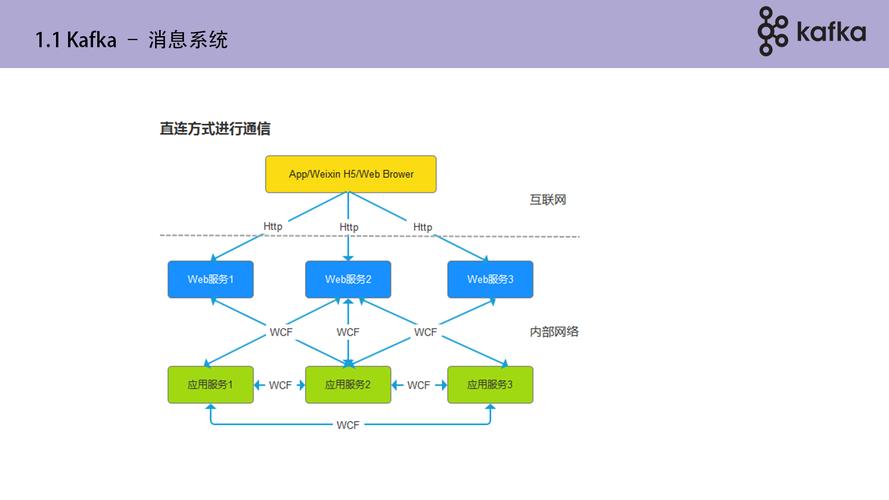

1、核心特性
高吞吐量: Kafka设计之初即考虑到了高吞吐量的需求,它能高效地处理海量消息,支持多生产者和多消费者同时工作,从而满足大数据场景下对数据处理能力的要求。
可扩展性: Kafka的可扩展性体现在其能够轻松增加更多的分区和服务器来容纳更多的数据和负载,这种水平扩展能力使得Kafka能够随着业务需求的增长而增长。
分布式: Kafka是一个分布式系统,可以在多台服务器上运行,分布式的特性保证了系统的高可用性和容错能力,即使某一部分系统出现问题,整体仍然可以继续工作。
基于Zookeeper: Kafka 依赖于 Zookeeper 来进行集群的协调和管理,Zookeeper 帮助 Kafka 在集群中进行领导选举、节点同步等关键操作。
2、基础概念
消息: Kafka 中的数据单元被称为消息,也即记录,这些消息被发送到特定的主题中,消费者可以从这些主题中读取消息。
主题: 可以理解为消息的分类或通道,生产者将消息发送到特定的主题,而消费者则订阅这些主题以接收消息,每个主题可以分为多个分区,以提高并行度和容错能力。
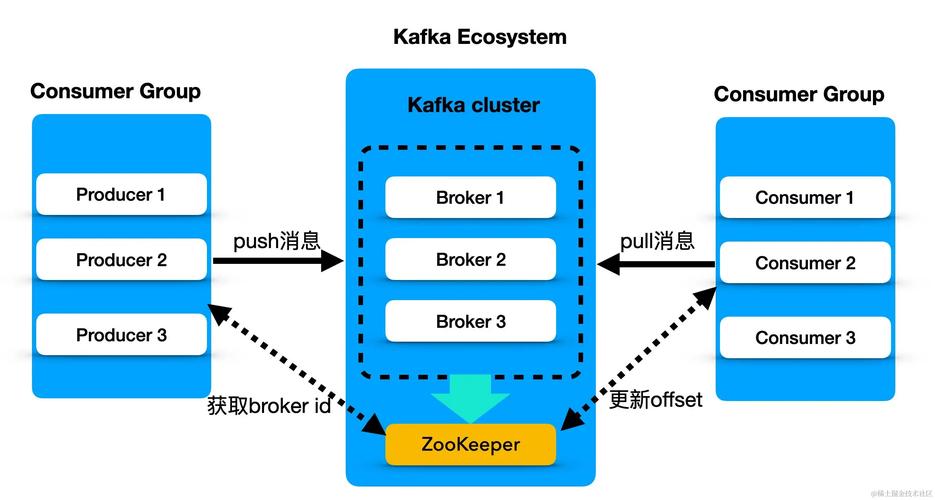
分区: 分区是主题的细分,每个分区可以在不同的服务器上独立存在,这允许主题跨越多个服务器,从而提高了集群的消息吞吐量和容错能力。
副本: 为了提高系统的可靠性,Kafka允许对分区创建副本,如果一个分区失败,系统会自动切换到副本分区继续工作,以此保证服务的持续性和稳定性。
3、应用场景
实时数据管道: Kafka常用于构建实时数据处理管道,特别是在需要处理大量数据流的应用中,如日志聚合、指标监控等。
流式数据处理: Kafka 优秀的流处理能力使其成为实时流式数据处理的首选,能够支持复杂的事件处理、数据分析等操作。
应用解耦: Kafka可以作为系统间的缓冲区,减少系统间直接的耦合,提高整体架构的灵活性和稳定性。
流量削峰去谷: 在面对高流量和不确定的负载时,Kafka可以作为缓冲层,稳定后端服务的流量,确保系统平稳运行。
可以看出Kafka不仅是一个高性能的消息队列系统,而且通过其独特的设计,提供了高度的可靠性、扩展性和分布式处理能力,这使得Kafka成为了处理大规模数据流和实时消息传递的理想选择。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复