
机器学习中的端到端场景指的是从原始数据输入到最终结果输出的整个流程,这个过程中可能包括数据准备、模型训练、服务部署等环节,下面将具体介绍机器学习中端到端场景的详细步骤:
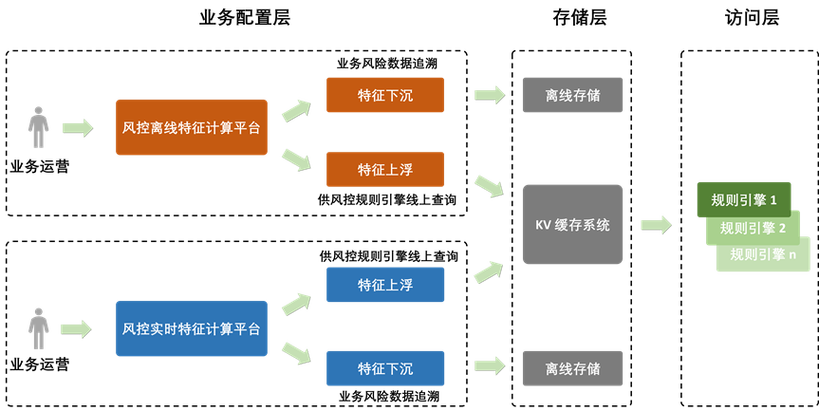

1、数据理解和收集
数据来源:确定数据来源,例如公开数据集、公司内部数据或通过爬虫采集的数据。
数据理解:对数据进行初步分析,了解数据的基本信息,如总体数量、特征类型以及缺失值情况等。
2、数据清理和预处理
数据清洗:处理缺失值、异常值和重复值等问题,确保数据质量。
数据转换:根据模型需求进行数据编码、归一化或标准化等操作。
3、特征工程
特征提取:从原始数据集中提取有用的信息作为模型的输入特征。
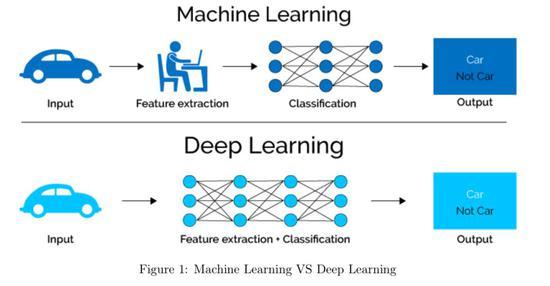
特征选择:通过统计分析或基于模型的特征重要性进行特征选择,去除不相关或冗余的特征。
4、模型训练和调优
模型选择:根据问题类型选择合适的模型,如分类、回归或聚类等。
超参数调优:使用网格搜索、随机搜索或贝叶斯优化等方法寻找最优的超参数组合。
5、模型评估
评估指标:根据问题类型选择合适的评估指标,如准确率、召回率、F1分数或均方误差等。
交叉验证:使用交叉验证等方法评估模型的泛化能力。
6、模型部署和服务化
模型部署:将训练好的模型部署到生产环境,如云端服务器或边缘设备。
服务接口:开发API接口,使模型能够接收外部请求并返回预测结果。
7、模型监控和维护
性能监控:定期检查模型的性能,确保其稳定性和准确性。
模型更新:根据数据的变化和反馈对模型进行迭代更新。
8、持续学习和改进
反馈循环:建立从用户反馈到模型改进的闭环,不断提升模型性能。
技术跟踪:关注最新的机器学习研究成果和技术发展,及时将先进技术应用到实践中。
在机器学习端到端场景中,每个步骤都有其重要性,且相互之间紧密联系,数据的质量直接影响到模型的性能,而特征工程的好坏又决定了数据潜力能否被充分挖掘,模型训练和调优是提高模型性能的关键,而模型的部署和监控则是确保模型长期稳定运行的保障。
在端到端场景中,还需要注意以下几个方面:
数据隐私和安全:在数据收集和处理过程中,要遵守相关法律法规,保护用户隐私。
模型可解释性:在特定领域,如金融或医疗,模型的可解释性尤为重要,需要关注模型的决策过程是否透明。
技术选型:根据项目需求和团队能力合理选择技术和工具,避免盲目追求最新技术而忽视实际应用效果。
机器学习端到端场景是一个涵盖数据准备、模型训练、服务部署等多个环节的完整流程,在实际操作中,需要根据具体任务的特点和要求,灵活运用各种技术和方法,不断优化和改进,以实现最佳的学习效果,随着技术的发展,新的工具和方法不断涌现,机器学习的实践也在不断进化,保持学习和创新是机器学习领域不可或缺的一部分。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复