
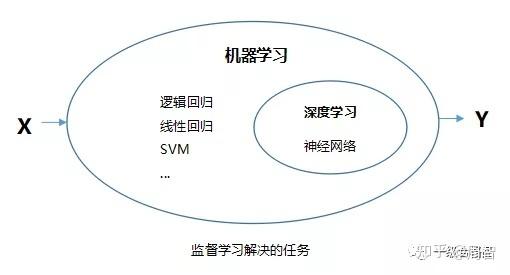
非神经网络机器学习(NonNeural Machine Learning)是一种不依赖于神经网络的机器学习方法,与神经网络不同,非神经网络机器学习算法通常基于传统的数学模型和统计方法,通过特征工程和模型训练来构建预测模型。
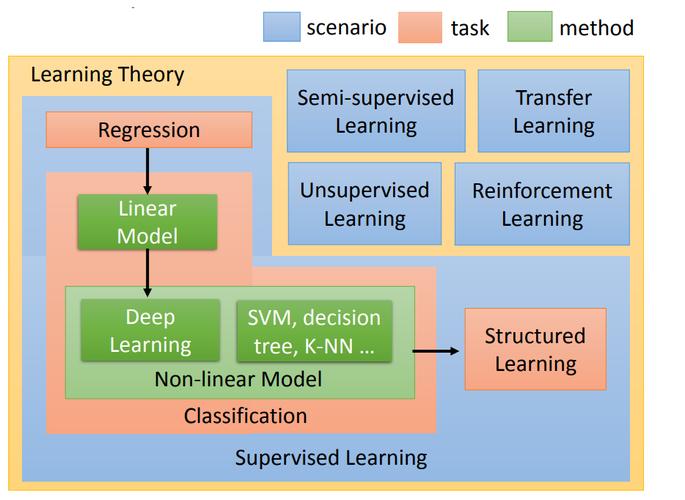

在机器学习端到端场景中,非神经网络机器学习算法可以用于解决各种问题,包括分类、回归、聚类等,下面将详细介绍一些常见的非神经网络机器学习算法及其应用场景。
1、决策树(Decision Trees)
决策树是一种常用的分类和回归算法,它通过递归地分割数据集来构建一棵树形结构,每个节点表示一个特征或属性,每个分支表示一个决策规则,每个叶节点表示一个类别或数值,决策树具有可解释性强、易于理解和实现的优点。
2、支持向量机(Support Vector Machines)
支持向量机是一种用于分类和回归的监督学习算法,它通过找到一个最优的超平面来将不同类别的数据点分开,支持向量机具有较好的泛化能力和高维数据处理能力。
3、随机森林(Random Forests)
随机森林是一种集成学习方法,它通过构建多个决策树并取其平均结果来进行分类和回归,随机森林能够有效地处理高维数据和大量数据样本,并且具有较高的准确性和鲁棒性。
4、K近邻算法(KNearest Neighbors)
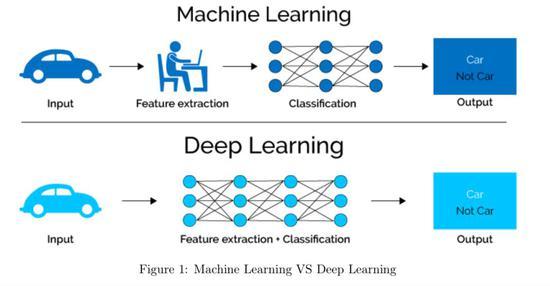
K近邻算法是一种基于实例的学习方法,它通过计算待分类数据点与已知类别数据点之间的距离,选取距离最近的K个邻居,然后根据邻居的类别进行投票或加权平均来进行分类,K近邻算法简单易用,但需要选择合适的距离度量和邻居数量。
5、逻辑回归(Logistic Regression)
逻辑回归是一种用于二分类问题的线性分类器,它通过使用逻辑函数来建立输入特征与输出概率之间的非线性关系,逻辑回归具有较好的可解释性和高效性,适用于大规模数据集和在线学习场景。
6、主成分分析(Principal Component Analysis)
主成分分析是一种用于降维和特征提取的无监督学习算法,它通过线性变换将原始特征转换为一组新的正交特征,保留了原始数据的主要信息,主成分分析常用于数据压缩、可视化和特征选择等任务。
7、聚类算法(Clustering Algorithms)
聚类算法是一种无监督学习算法,用于将数据集划分为若干个相似的组或簇,常见的聚类算法包括K均值聚类、层次聚类和密度聚类等,聚类算法常用于数据分析、模式识别和图像分割等领域。
相关问题与解答:
1、非神经网络机器学习算法是否比神经网络机器学习算法更准确?
答:无法一概而论,非神经网络机器学习算法在某些问题上可能更准确,例如对于小规模数据集和简单问题,非神经网络机器学习算法可能更容易得到较好的结果,而对于大规模数据集和复杂问题,神经网络机器学习算法可能更具优势,因为它能够自动学习和提取特征。
2、非神经网络机器学习算法是否更易于理解和解释?
答:是的,相对于神经网络机器学习算法,非神经网络机器学习算法通常更易于理解和解释,非神经网络机器学习算法通常基于明确的数学模型和统计方法,可以通过可视化和特征重要性等方式来解释模型的决策过程和结果。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复