
在当今技术快速发展的时代,机器学习已成为推动人工智能领域前进的关键技术之一,端到端的机器学习场景不仅包括了从数据处理、模型选择、训练优化到最后的部署实施的全过程,还涵盖了项目管理和后期维护等多个方面,本文将以图像分类为例,详细解析机器学习项目从开始到结束的完整流程,帮助初学者和项目实施者更好地理解和掌握这一复杂但极具前景的技术路径。
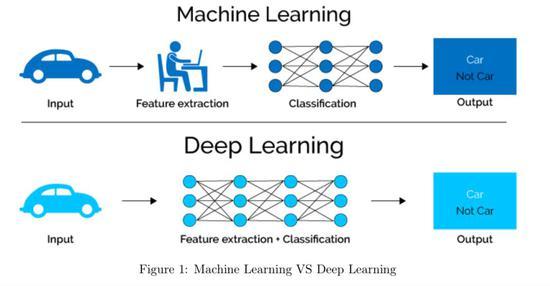

一、数据准备与预处理
1. 数据标注
图像分类案例:在图像分类项目中,数据标注是首要步骤,标注的质量直接影响模型的学习效果和最终的准确率,AI Gallery提供的“图像分类ResNet_v1_50工作流”就包含了详细的标注指导和工具使用说明,确保输入模型的数据是准确和高效的。
标注工具和技术:使用自动化工具进行数据的标注可以大大提高效率,如使用半自动化的标注软件,通过机器学习辅助提高标注速度,同时保证标注质量。
处理不确定性和异常值:在数据标注过程中,需要特别注意异常值和不确定性高的数据点,这要求标注人员具备一定的专业知识,以识别并正确处理这些特殊情况。
2. 数据增强
增强技术的应用:为了提升模型的泛化能力,数据增强技术被广泛应用于图像和其他类型的数据上,图像分类中常用的增强方法包括旋转、缩放、裁剪等,这可以有效地扩充训练数据集,提高模型对新数据的适应能力。
程序自动生成:利用现有的库和框架,如TensorFlow和PyTorch,可以编程实现数据增强,自动化这一过程,使其成为预处理的一部分。
处理不同数据源:针对不同来源的数据,调整数据增强策略以适应不同的特征和需求,这对于保持数据的一致性和提高模型性能至关重要。
3. 探索性数据分析
统计特性分析:通过统计分析,了解数据的分布、均值、方差等特性,这对于选择合适的预处理步骤和模型架构非常关键。
可视化操作:运用图表和可视化工具帮助理解数据的结构,例如使用散点图、直方图等展示数据的分布情况。
二、模型选择与训练
1. 模型架构设计
根据问题选择模型:不同的机器学习问题(如分类、回归、聚类)需要不同的模型结构,图像分类问题常常使用卷积神经网络(CNN)。
自定义模型结构:在一些特定的应用中,可能需要自定义模型架构,比如增加或减少网络层的数量,调整层的参数等。
预训练模型的使用:使用已经在大型数据集上预训练过的模型如ResNet, VGG等,可以加速训练过程并提高模型性能。
2. 超参数调优
网格搜索:使用网格搜索等技术系统地试验不同超参数组合,找到最优的参数设置。
随机搜索:作为一种替代方法,随机搜索可以在更大的参数空间内进行更有效率的搜索。
贝叶斯优化:这是一种更先进的技术,用于在参数空间中寻找最优解,特别适合于高维和复杂的搜索空间。
3. 训练策略
批处理与在线学习:决定是使用批量更新还是在线更新参数,这取决于数据量和计算资源。
学习率调整:适当调整学习率,可以使用学习率衰减或者自适应学习率方法来改善训练过程。
正则化技术:使用L1、L2正则化或辍落out等技术防止过拟合,提高模型的泛化能力。
三、服务部署与优化
1. 部署策略
云平台部署:利用华为云等平台进行模型的部署,这些平台提供了丰富的工具和支持,使部署变得更加容易和高效。
容器化:使用Docker等容器技术,可以使得应用更加容易在不同的环境中移植和扩展。
自动伸缩:结合云服务的自动伸缩功能,可以根据负载自动调整资源,优化成本和性能。
2. 性能监控与优化
监控工具:使用Prometheus等监控工具跟踪应用的性能指标,如响应时间、系统负载等。
日志管理:合理配置日志收集与管理策略,使用ELK Stack等解决方案,可以帮助快速定位和解决问题。
反馈循环:建立从用户反馈到产品迭代的快速通道,持续优化模型和服务的性能。
3. 安全性和合规性
数据加密:确保传输和存储的数据都进行加密处理,保护用户数据的安全。
合规性检查:遵守GDPR、ISO27001等国际安全和隐私保护标准,确保服务的合法合规。
访问控制:实施严格的访问控制和身份验证机制,确保只有授权用户可以访问敏感数据和功能。
机器学习的端到端实施是一个涉及多个环节的复杂过程,每个阶段都需要精心设计和执行,以确保最终的模型效能和服务的可靠性,希望本文提供的指南能为您的机器学习项目提供参考和帮助,在此基础上,提出以下两个相关问题及其解答:
Q1: 如何选择合适的机器学习模型?
A1: 选择合适的机器学习模型应考虑数据的特征、问题的类型(如分类或回归)、以及可用的计算资源,可以通过查看相关文献、实验不同模型和参数来找到最适合当前问题的模型。
Q2: 数据预处理中常见的陷阱有哪些?
A2: 常见的陷阱包括忽略数据质量的评估、未正确处理缺失值和异常值、以及未能适当地进行特征归一化或标准化,这些都可能导致模型性能不佳或结果不稳定。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复