
多变量分析机器学习是一种利用多个输入变量来预测一个或多个输出变量的机器学习技术,在端到端场景中,从数据预处理到模型训练和最终的预测,整个流程需要精确的设计和优化,下面将详细介绍这一过程的各个关键步骤。
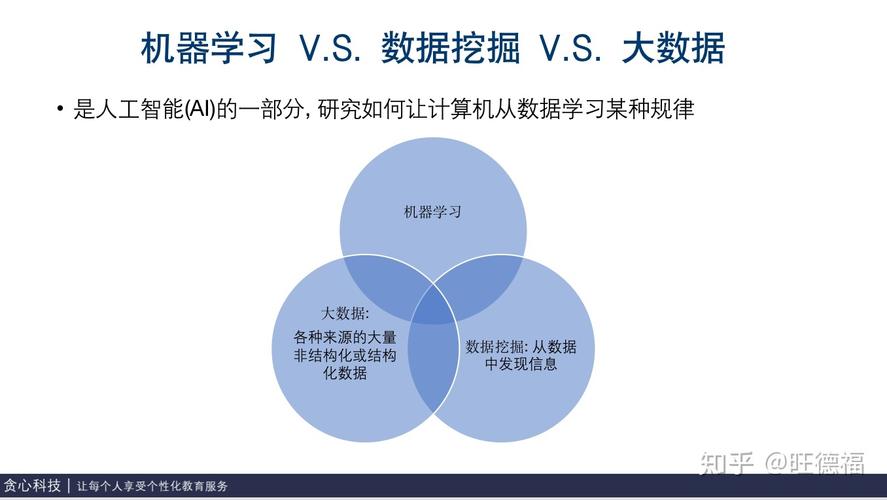

1、数据收集与预处理
数据收集: 确定需要预测的目标变量后,收集相关的多维数据,预测房价可能需考虑面积、卧室数量、地理位置等因素。
数据清洗: 去除冗余和错误的数据条目,确保数据质量。
特征工程: 包括特征选择和特征转换,以识别最有影响力的特征并提升模型性能。
2、选择合适的模型架构
线性和非线性模型: 对于多变量问题,可以采用多种模型,如多变量线性回归模型,它通过向量化实现,有效处理多个变量。
深度学习模型: LSTM结构的拓展版本和基于Transformer的模型如SageFormer可以捕获变量间的复杂动态。
3、模型训练与验证
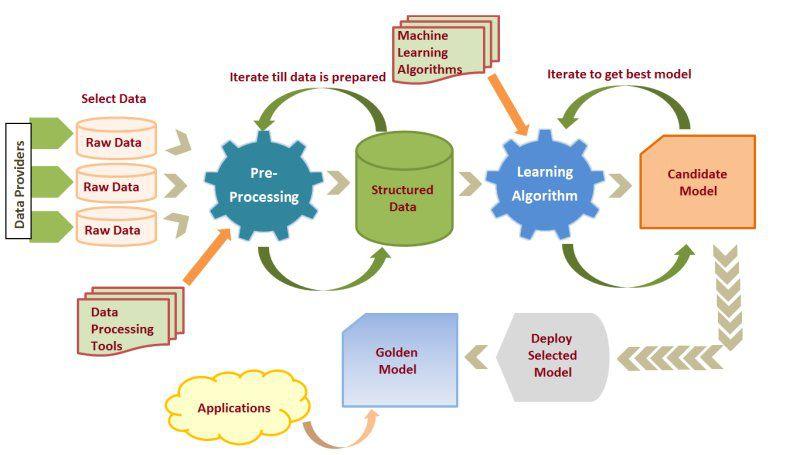
训练集和验证集的划分: 数据集通常分为训练集用于模型学习,验证集用于模型评估和调优。
超参数调整: 通过调整学习率、层数等超参数优化模型性能。
交叉验证: 使用交叉验证技术减少过拟合的风险,提高模型的泛化能力。
4、模型评估
性能指标: 使用如均方误差(MSE)、决定系数(R²)等指标评价模型性能。
对比试验: 与其他模型进行对比试验,确保选用的模型具有最优表现。
5、部署与应用
模型部署: 将训练好的模型部署到生产环境,实时处理新的数据预测。
监控与维护: 定期检查模型的准确性和性能,根据需要进行微调。
6、案例研究与实际应用
商业分析: 在金融领域,多变量分析可用于预测股价、评估信用风险等。
医疗健康: 在医疗行业,通过分析病人的多项生理指标来预测疾病风险。
相关问题与解答栏目:
Q1: 如何选择合适的机器学习模型解决多变量问题?
A1: 选择模型时需考虑问题的复杂度和数据的特性,简单问题可选用线性回归,复杂问题可考虑深度学习,特别是当变量间存在复杂的动态关系时,LSTM或Transformer基模型可能是更好的选择。
Q2: 如何处理多变量数据中的缺失值?
A2: 数据预处理阶段应进行缺失值处理,常用方法包括删除含有缺失值的行、使用均值/中位数填充、或采用更复杂的插补技术如多重插补。
归纳而言,多变量分析机器学习是一个包含多个步骤的复杂过程,从数据的预处理到模型的选择和优化,每一步都需要精心设计,理解每个步骤的重要性及其对最终结果的影响是成功实施的关键。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复