
分布式文件系统是一种通过网络连接多个计算机节点,共同提供高性能、高可用和可扩展的文件存储服务的软件系统,在当今数据量激增的时代背景下,单机文件系统已难以满足海量数据处理需求,分布式文件系统以其独特的架构设计解决了这一挑战,下面将深入探讨分布式文件系统的产品架构:
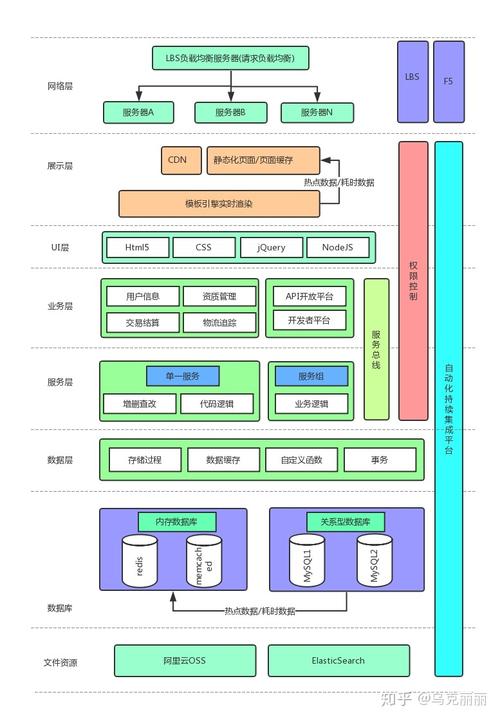

1、基本架构
客户端与服务器端: 分布式文件系统采用Client/Server架构,其中客户端负责向服务器端发送请求并处理数据,服务器端则负责数据的实际存储和管理。
数据分块与副本机制: 为保证数据的可靠性与系统的容错性,分布式文件系统通常会将数据分块(chunking),每个数据块(block)会有多个副本(replication)分布在不同的节点上。
元数据管理: 元数据是描述文件属性与结构的信息,分布式文件系统中的元数据通常由一个或多个专门的节点管理,这些节点负责处理文件创建、删除、映射等操作。
2、典型产品分析
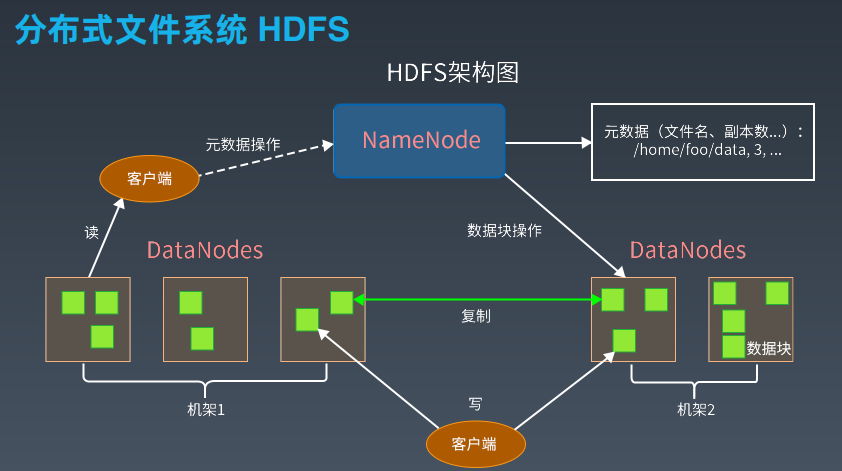
Hadoop Distributed File System (HDFS): HDFS是一个高度容错的系统,设计用于运行在通用硬件上的分布式文件系统,它能够提供高吞吐量的数据访问,非常适合于离线数据处理任务。
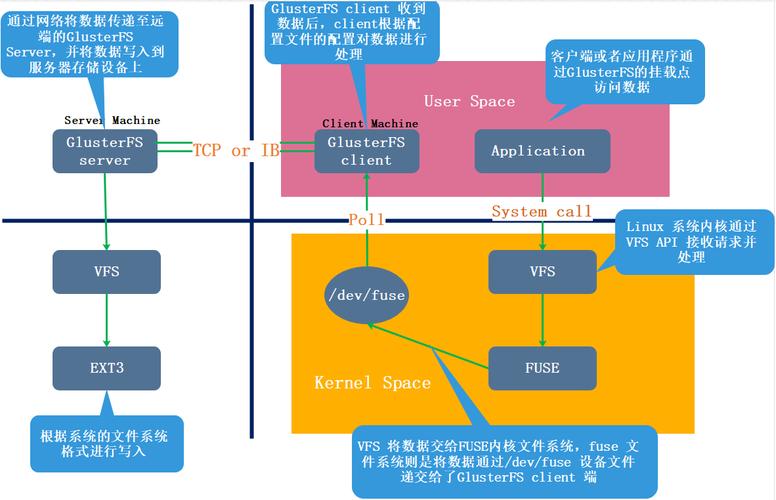
GlusterFS: GlusterFS支持POSIX规范,它是一个容量可扩展的分布式文件系统,可以通过添加更多的节点来扩展存储容量,GlusterFS使用弹性哈希数据分布技术,不需要元数据服务器,而是利用所有服务器资源。
3、网络通信机制
TCP/IP协议: 分布式文件系统的各个节点之间通过TCP/IP协议进行网络通信,确保数据传输的稳定性与可靠性。
数据一致性协议: 如Paxos与Raft等协议,用来解决分布式系统中数据一致性的问题,保证在发生故障时系统的正常运行。
4、数据存储策略
条带化(RAID)技术: 条带化技术可以将数据跨多个硬盘或节点分布,提升I/O性能及容错能力。
纠删编码(Erasure Coding): 相较于传统的多副本机制,纠删编码是一种更高效的数据保护技术,能够在保证数据可靠性的同时减少存储空间的消耗。
5、性能优化措施
缓存机制: 客户端和服务器端都会采用缓存机制来减少I/O操作,提高系统响应速度。
负载均衡: 分布式文件系统会监控各节点的工作负载,并通过算法动态分配数据和请求,以达到负载均衡的目的。
在分布式文件系统的设计中,还需考虑以下几个方面:
可伸缩性: 系统应能适应不断增长的数据量,支持在线扩容,而无需停机维护。
安全性: 需要实现严格的权限控制和加密措施,保护数据不被非法访问和篡改。
成本控制: 在满足性能要求的前提下,尽可能选择成本效益高的存储与计算资源。
可以看到分布式文件系统在设计上追求的是高性能、高可用性和自我恢复能力,同时注重资源的高效利用和成本控制,随着云计算、大数据等技术的不断发展,分布式文件系统正成为支撑这些应用的重要基础架构,对于企业而言,正确选择和优化分布式文件系统,可以极大提升数据处理能力,为企业的数字化转型提供有力支持。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复