
分布式大数据_数据分布式存储

概述
在当今数据驱动的世界中,分布式大数据处理和存储变得至关重要,随着数据量的爆炸性增长,传统的集中式存储系统已经无法满足处理海量数据的需求,分布式存储系统被设计出来,以支持横向扩展、高可用性和容错能力。
核心概念
数据分片(Sharding)
数据分片是将大型数据集分割成更小的、可管理的块的过程,这些块可以分散到多个服务器上,每个分片通常包含一定范围内的数据项,并且可以在独立的服务器节点上进行处理。
复制(Replication)
为了提高数据的可靠性和可用性,分布式存储系统通常会将数据复制到多个物理位置,这可以防止数据丢失,并在一个节点失败时提供冗余。
一致性(Consistency)
在分布式系统中,保持数据的一致性是关键挑战之一,一致性模型定义了系统在一定条件下的行为,例如在网络分区或节点故障后如何恢复数据。
容错(Fault Tolerance)
分布式系统必须能够应对节点故障而不影响整体功能,这通常通过副本和分布式协议来实现,以确保当部分系统失效时,整个系统仍然可以继续运行。
分布式存储类型
键值存储(KeyValue Stores)
这类系统允许用户通过唯一的键来存储和检索数据,它们通常提供简单的API和高效的查询性能。
文档存储(Document Stores)
文档存储是键值存储的一种形式,其中值是结构化的文档,它们通常使用JSON或BSON格式,并提供对文档内部结构的查询能力。
列式存储(Columnar Stores)
列式存储将数据按列而不是行进行组织,这使得读取大量行的特定列变得非常高效,非常适合于数据分析工作负载。
数据库系统(Distributed Database Systems)
分布式数据库系统提供了一种方式来跨多个节点分布和协调事务,支持复杂的查询和ACID(原子性、一致性、隔离性、持久性)保证。
技术实现
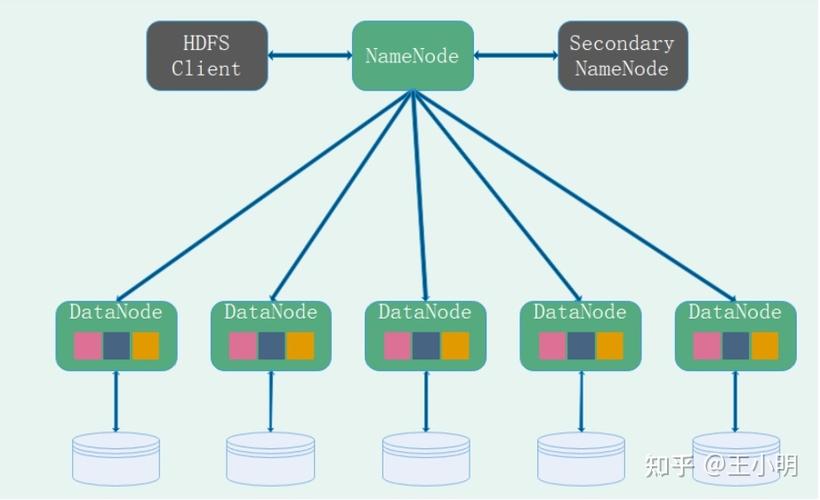
分布式文件系统
如HDFS(Hadoop Distributed File System),它提供了高吞吐量的数据访问,非常适合大规模数据集上的批量处理任务。
对象存储
对象存储系统如Amazon S3,提供了简单的Web服务接口来存储和检索大量的非结构化数据。
新型存储系统
如Cassandra和MongoDB,这些系统结合了多种存储模型的特点,旨在提供高性能和高可用性。
相关技术和工具
Hadoop: 一个开源框架,用于分布式处理大数据集。
Spark: 一个快速的通用集群计算系统。
Ceph: 一个可扩展的分布式存储系统。
Apache Cassandra: 高度可扩展和去中心化的NoSQL数据库。
表格:分布式存储系统比较
| 特性 | HDFS | Amazon S3 | Cassandra | MongoDB |
| 数据模型 | 文件系统 | 对象存储 | 键值/列存储 | 文档存储 |
| 一致性模型 | 强一致性 | 最终一致性 | 可调一致性 | 最终一致性 |
| 数据复制 | 是 | 是 | 是 | 是 |
| 分布式事务 | 不支持 | 不支持 | 有限支持 | 有限支持 |
| 适用场景 | 大数据批处理 | 云存储服务 | 实时应用 | Web应用 |
选择正确的分布式存储解决方案取决于特定的用例和需求,每种系统都有其优势和局限性,重要的是要理解你的数据访问模式和一致性要求,以便为你的大数据应用选择最合适的存储策略。
问题与解答
1、问: 在设计分布式存储系统时,如何权衡一致性和可用性?
答: 在分布式存储系统中,根据CAP定理(Brewer的CAP理论),一致性(Consistency)、可用性(Availability)和分区容忍性(Partition Tolerance)三者不可兼得,设计时需考虑业务需求:若需要高可用性,可能需牺牲一定的一致性;若数据准确性至关重要,则需强化一致性保证,实践中常采用最终一致性模型,在保证系统整体可用的同时,逐渐同步数据以达到最终一致状态。
2、问: Hadoop HDFS与传统文件系统有何不同?
答: Hadoop HDFS是为处理大规模数据集而设计的分布式文件系统,具有高吞吐量的数据访问能力,适合批量处理任务,不同于传统文件系统,HDFS优化了对大型文件的存储,通过数据分块和副本机制实现容错和可靠性,HDFS放松了POSIX约束,简化了一致性模型,以适应大规模分布式环境的需求。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复