
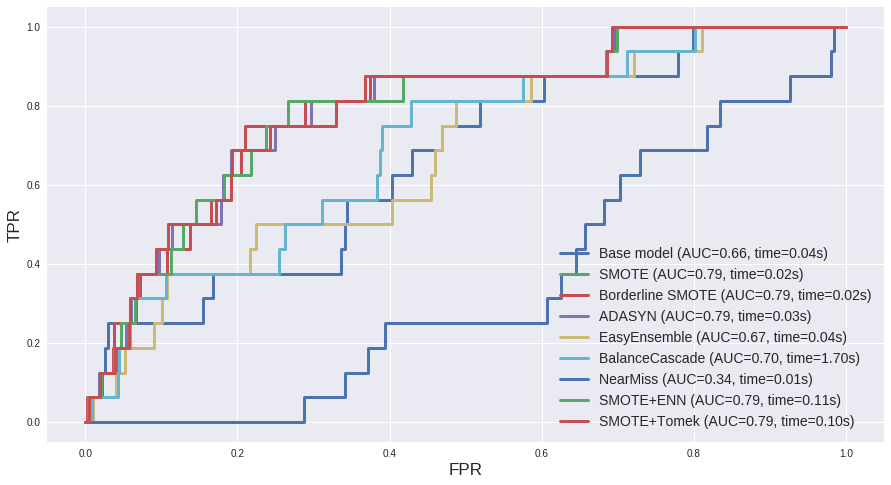
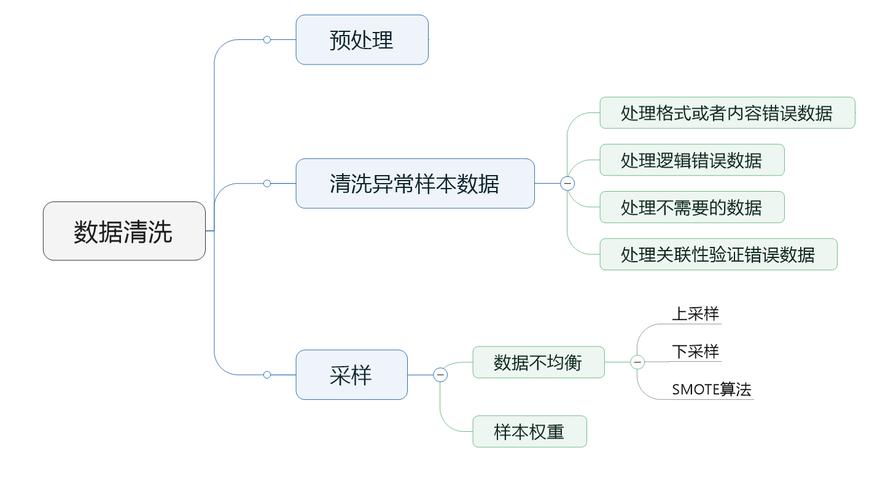
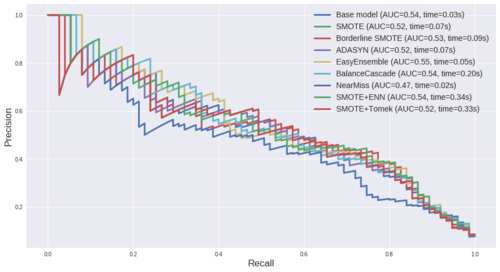
在机器学习中,特征清洗(Feature Cleaning)是非常重要的一步,它可以帮助提高模型的性能和准确性,特征清洗主要包括以下几个方面:

1、缺失值处理:数据集中可能存在缺失值,需要对其进行填充或删除,常用的方法有:
均值/中位数/众数填充:对于数值型特征,可以用均值或中位数填充;对于类别型特征,可以用众数填充。
插值法:如线性插值、多项式插值等。
删除含有缺失值的行或列:如果缺失值较少,可以考虑删除含有缺失值的行或列。
2、异常值处理:数据集中可能存在异常值,需要对其进行识别和处理,常用的方法有:
箱线图:通过绘制箱线图,可以直观地看出数据中的异常值。
Zscore:计算每个数据点与均值的距离,距离超过阈值的数据点被认为是异常值。
IQR(四分位距):计算数据的上下四分位数,位于上下四分位数之外的点被认为是异常值。
3、数据标准化/归一化:将数据缩放到相同的尺度,使得模型训练更加稳定,常用的方法有:
最小最大标准化(MinMax Scaling):将数据缩放到[0, 1]区间。
标准化(Standardization):将数据转换为均值为0,标准差为1的分布。
归一化(Normalization):将数据缩放到[1, 1]区间。
4、编码类别型特征:将类别型特征转换为数值型特征,以便模型能够处理,常用的方法有:
独热编码(OneHot Encoding):将每个类别转换为一个二进制向量,每个向量只有一个位置为1,其余位置为0。
标签编码(Label Encoding):将每个类别分配一个整数,按顺序排列。
计数编码(Count Encoding):统计每个类别出现的次数,用次数代替类别。
5、特征选择:从原始特征中选择对模型预测有帮助的特征,减少模型复杂度,常用的方法有:
过滤法(Filter Method):根据统计检验或相关性分析选择特征。
包装法(Wrapper Method):使用模型的性能作为特征选择的标准,如递归特征消除(Recursive Feature Elimination, RFE)。
嵌入法(Embedded Method):在模型训练过程中自动进行特征选择,如Lasso回归、决策树等。
6、特征变换:将原始特征转换为新的特征,以提高模型的性能,常用的方法有:
多项式特征(Polynomial Features):将原始特征的多项式组合作为新的特征。
交互特征(Interaction Features):将不同特征的乘积作为新的特征。
分桶(Binning):将连续特征划分为离散的区间,用区间代替原始特征。
就是特征清洗的一些常用方法,实际应用时需要根据数据集的特点和模型需求选择合适的方法进行处理。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复