
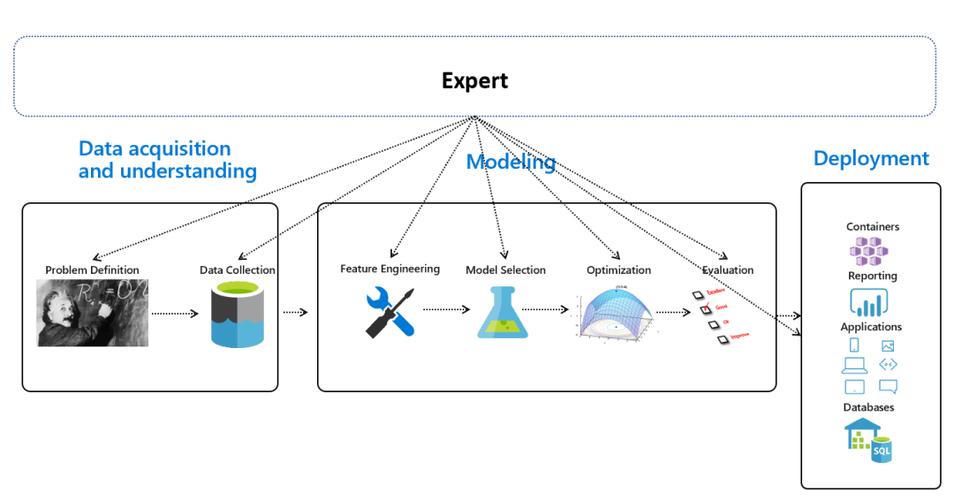
在当今数字化时代,机器学习技术的应用已经渗透到各行各业,其中风险评估是机器学习技术大显身手的一个重要领域,机器学习在这一领域的应用不仅提高了评估的效率和准确性,还为预测和防范潜在风险提供了强有力的工具,下面将深入探讨机器学习在风险评估中的端到端场景:

1、需求分析
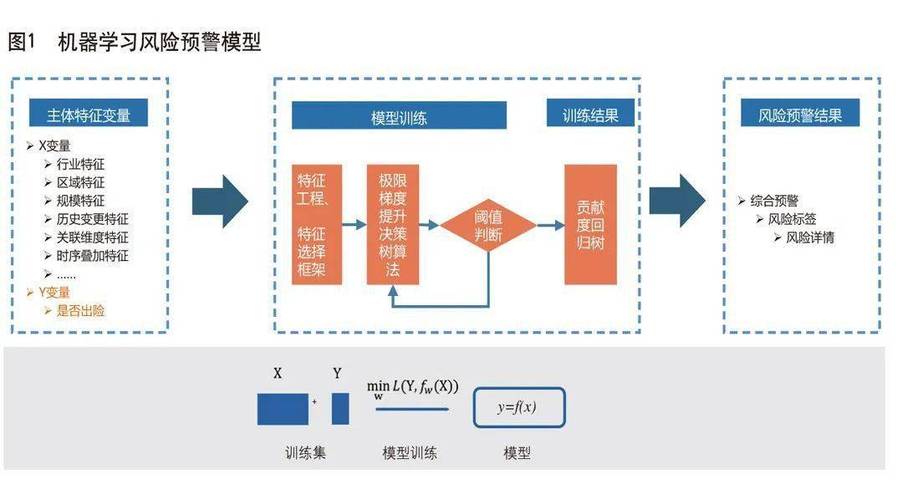
确定风险评估目标:确定机器学习模型的目的是为了预测风险发生的概率。
明确应用场景:金融数据风险评估、企业风险管理等。
2、数据收集与预处理
数据采集:收集历史交易数据、用户行为数据等作为训练和测试的数据源。
特征工程:通过数据预处理提取有用的特征,如交易金额、交易时间、用户信用评分等。
数据清洗:处理缺失值、异常值,标准化或归一化数据。
3、模型选择与训练
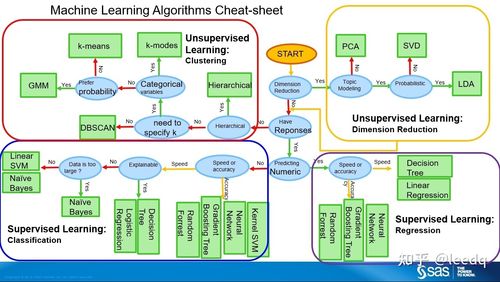
算法选择:根据问题的性质选择合适的机器学习算法,如逻辑回归、随机森林、SVM等。
模型训练:使用已标注的数据集训练选定的机器学习模型。
4、模型评估与优化
交叉验证:通过交叉验证来评估模型的泛化能力。
参数调优:调整模型参数,如正则化项、学习率等,以提高模型性能。
5、风险预测与解释
风险评分:利用模型对新的数据进行风险评分,预测其发生风险交易的概率。
结果解释:解释模型的预测结果,提供可操作的洞察。
6、部署与监控
模型部署:将训练好的模型部署到生产环境中。
性能监控:持续监控模型的性能,确保其稳定性和准确性。
7、反馈与迭代
收集反馈:从实际应用中收集反馈,包括模型的预测效果和用户反馈。
模型迭代:根据反馈对模型进行调整和优化,以适应新的变化。
8、法规遵循与伦理考量
遵守法规:确保风险评估过程符合相关法律法规,如数据保护法。
伦理审查:考虑模型可能带来的伦理问题,如偏见和公平性。
在了解以上内容后,在整个端到端的场景中,有几个关键点需要注意:
数据的质量和代表性:确保训练数据的质量对于模型的准确性至关重要,需要数据具有代表性,避免偏差。
模型的可解释性:在风险评估领域,模型的可解释性非常重要,因为它可以帮助理解模型的决策过程,并在实际运用中提供依据。
持续监控和维护:模型部署后,需要定期检查其性能,以确保随着数据的变化,模型仍然有效。
机器学习在风险评估中的应用是一个系统的过程,涉及从需求分析到模型部署的多个步骤,通过精心设计和执行这些步骤,可以构建出既准确又可靠的风险评估模型,为企业提供强大的风险管理工具,随着技术的发展和数据保护法规的更新,风险评估模型也需要不断地迭代和优化,以适应不断变化的环境。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复