
emily fox 机器学习端到端场景


概述
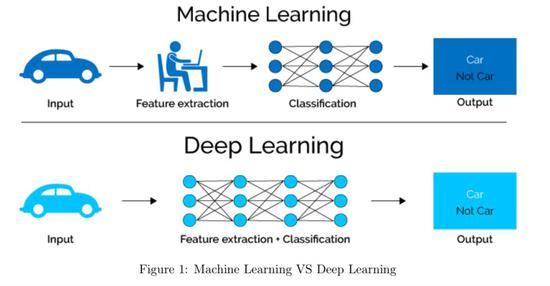
在当今的机器学习领域,端到端的深度学习引起了广泛的关注,这种方法的核心在于它能够简化数据处理流程,将传统多阶段处理的任务整合进一个连续的过程中,从而提高效率并减少错误,通过端到端的深度学习模型,从原始数据的输入到最终结果的输出,整个流程得以无缝连接。
核心步骤解析
数据标注
在端到端的学习过程中,数据标注是首要步骤,特别是在监督学习中,精确的数据标注直接影响模型的训练效果,在图像分类任务中,不同的图像需要被正确标记以属于特定的类别,这一过程往往需要领域知识或通过专门的标注软件来完成。
模型训练
模型训练是端到端系统开发中的关键环节,选择一个合适的预训练模型,如ResNet_v1_50,可以大大缩短开发周期和提高模型性能,使用深度学习框架,如TensorFlow或PyTorch,可以方便地加载预训练模型,并在此基础上进行微调。
服务部署
模型训练完成后,下一步是将训练好的模型部署为可以使用的服务,这可以通过多种方式实现,例如使用云服务如AWS SageMaker或Azure Machine Learning,部署后的模型可以接受新的输入数据,进行实时预测。
实操案例
以《HandsOn Machine Learning with ScikitLearn & TensorFlow》一书中介绍的项目为例,可以看到从问题定义、数据准备、选择算法、训练模型到最终部署和维护的全过程,书中不仅理论详尽,同时附有代码实例,使读者能够跟随步骤实操,加深理解。
挑战与解决方案
一个常见的挑战是在数据准备阶段的处理不当,可能会导致模型训练的效果不佳,解决这一问题的策略包括使用更复杂的数据增强技术,以及采用自动数据标注工具来提高标注的准确率和效率。
未来趋势
随着技术的不断进步,未来的端到端系统将更加智能化,能够自动调整模型参数以适应不同类型的数据和任务,随着计算资源的增加和算法的优化,处理大规模数据集的能力也将得到显著提升。
相关问题与解答

Q1: 如何选择合适的深度学习框架?
A1: 选择深度学习框架时,应考虑其社区支持、易用性、以及与其他工具的兼容性,TensorFlow 和 PyTorch 都是优秀的选择,具有丰富的教程和文档。
Q2: 如何处理不平衡的数据?
A2: 对于不平衡的数据,可以采用重采样技术,或者在损失函数中使用类权重来提高少数类的样本重要性。
端到端机器学习场景不仅涵盖了从原始数据到预测结果的完整流程,还包括了对模型的持续优化和迭代,通过实际操作案例和详细的步骤解析,可以更好地理解并应用这一方法。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复