
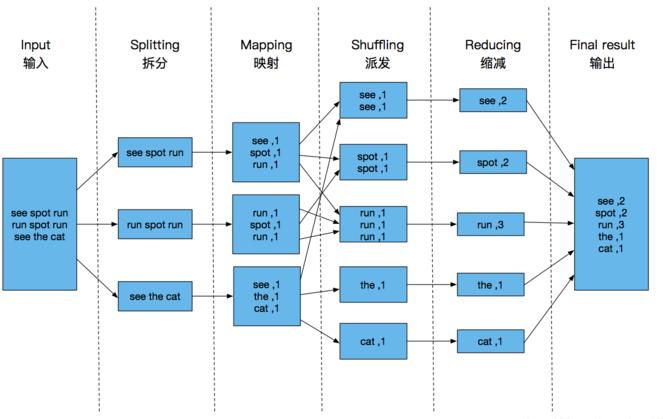
MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个主要阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块,然后每个块被一个map函数处理,在Reduce阶段,map阶段的输出结果被分组并传递给reduce函数进行处理。
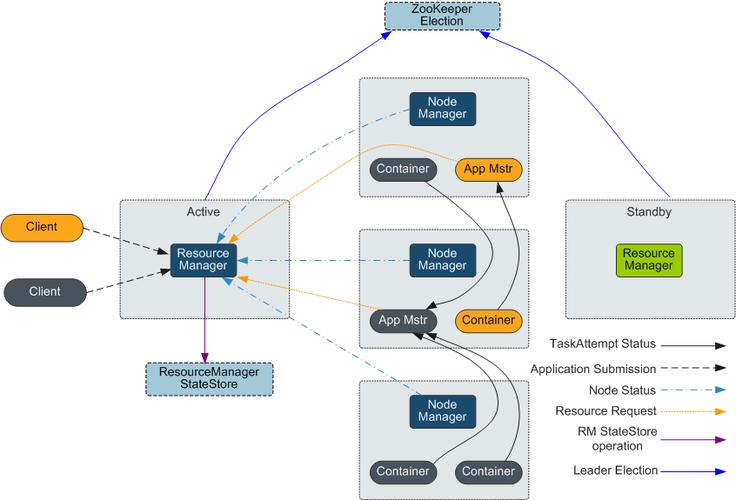

Dryad MapReduce是一个分布式计算框架,用于执行MapReduce任务,它提供了一个高性能、可扩展的平台,可以在集群中运行大规模数据处理任务,以下是使用Dryad MapReduce进行MapReduce任务的一般步骤:
1、安装和配置Dryad MapReduce环境:需要在集群上安装和配置Dryad MapReduce,这包括设置主节点(Master Node)和工作节点(Worker Nodes),以及配置网络和存储系统。
2、编写Map函数和Reduce函数:根据具体的数据处理需求,编写Map函数和Reduce函数,Map函数负责处理输入数据的单个块,而Reduce函数负责将Map阶段的输出结果进行汇总和处理。
3、准备输入数据:将待处理的数据上传到集群中的HDFS(Hadoop Distributed File System)或其他支持的文件系统中,确保数据格式正确,以便Map函数可以正确地读取和处理。
4、提交MapReduce作业:使用Dryad MapReduce的命令行工具或API提交MapReduce作业,提交作业时,需要指定输入数据的路径、Map函数和Reduce函数的类名以及其他相关参数。
5、监控作业执行:一旦作业提交成功,可以使用Dryad MapReduce提供的监控工具来跟踪作业的执行情况,这包括查看作业的状态、进度以及任何错误信息。
6、获取结果:当作业完成时,可以从HDFS或其他存储系统中获取处理后的结果,这些结果通常以文件的形式保存,可以根据需要进行进一步的处理或分析。
Dryad MapReduce是一个强大的分布式计算框架,可用于执行大规模的MapReduce任务,通过编写适当的Map函数和Reduce函数,可以将复杂的数据处理任务分解为可并行处理的小块,从而提高处理速度和效率。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复