
DistributedCache类来使用。将需要在各个节点间共享的文件添加到分布式缓存中,然后在map或reduce函数中通过Configuration对象获取该文件的本地路径,最后读取并使用该文件内容。在MapReduce中,广播变量是一种优化技术,允许用户在Map任务和Reduce任务之间共享只读数据,这种机制特别适用于那些需要让每个节点都能访问到的数据,如配置信息、查找表或机器学习模型的参数等。
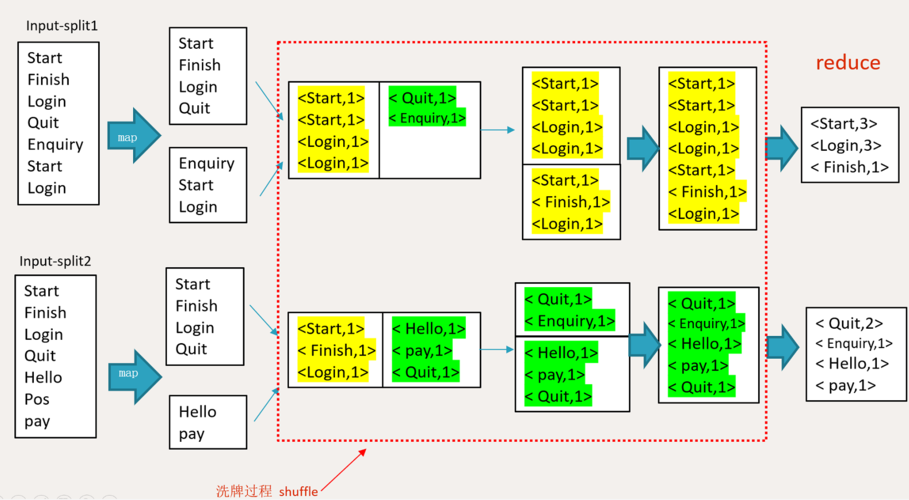

使用广播变量的原因
1、节省网络带宽:如果不使用广播变量,那么每份数据都需要通过网络发送给各个任务,这会消耗大量的网络带宽。
2、减少数据传输时间:广播变量只在作业开始时传输一次,减少了重复传输的时间。
3、内存优化:广播变量在每个节点上只存储一份,减少了内存的使用。
如何声明和使用广播变量
声明广播变量
在使用广播变量之前,首先需要在驱动程序中对其进行声明和初始化。
// 初始化广播变量 Broadcast<MyDataType> broadcastVar = jsc.broadcast(new MyDataType());
MyDataType是你自定义的数据类型,它可以是任何可序列化的类型。jsc是JobContext对象,通过它可以访问当前作业的配置信息。
在Map或Reduce任务中使用广播变量
一旦声明了广播变量,就可以在Map或Reduce任务中获取并使用它。
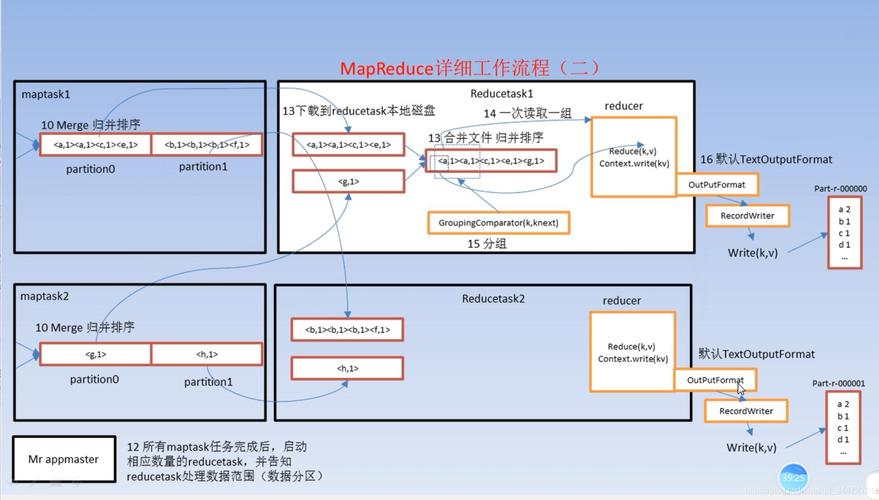
public void map(Writable key, Writable value, Context context) throws IOException, InterruptedException {
// 获取广播变量的值
MyDataType myData = context.getBroadcast().value();
// 使用广播变量进行操作
} 或者在Reduce任务中:
public void reduce(Writable key, Iterable<Writable> values, Context context) throws IOException, InterruptedException {
// 获取广播变量的值
MyDataType myData = context.getBroadcast().value();
// 使用广播变量进行操作
} 注意事项
确保你的广播变量实现了序列化接口,因为广播变量需要在网络间传输。
广播变量在每个Map或Reduce任务中只会被反序列化一次并存储在本地磁盘上,之后每次访问时都是从本地读取,不会重复传输。
广播变量是只读的,不能在Map或Reduce任务中修改它们。
相关问题与解答
Q1: 如果广播变量很大,会不会影响MapReduce作业的性能?
A1: 如果广播变量非常大,可能会对作业启动时间产生影响,因为所有节点都需要将这个变量加载到内存中,如果广播变量占用的内存超过了单个节点可用的内存,可能会导致作业失败,合理选择哪些变量需要广播是很重要的。
Q2: 广播变量是否适合存储频繁变动的数据?
A2: 不适合,由于广播变量是在作业开始时传输的,并且在整个作业期间保持不变,所以它们不适合存储需要频繁更新的数据,对于这类数据,考虑使用分布式缓存或其他数据共享机制可能更合适。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复