
在开发大数据处理应用程序时,Apache Hadoop的MapReduce框架是一个关键工具,为了提高开发效率和便利性,许多开发人员选择在Eclipse集成开发环境(IDE)中配置和运行MapReduce程序,下面将详细介绍如何在Eclipse中导入并配置一个MapReduce样例工程,具体涉及到插件准备、Eclipse配置、Map/Reduce配置等方面,具体的操作如下:

1、插件准备
下载hadoopeclipseplugin:需要下载hadoopeclipseplugin插件,这个插件使得Eclipse能够与Hadoop集群交互,方便地管理和运行MapReduce作业。
上传插件到虚拟机:如果你正在使用虚拟机进行开发,需要将下载的插件上传到虚拟机中,可以使用如scp或通过云盘等方式上传文件。
检查文件是否上传成功:在上传后,可以通过命令ls | grep hadoope来检查文件是否已成功上传到虚拟机的下载目录中。
2、Eclipse配置
启动Hadoop并复制插件:在虚拟机中启动Hadoop服务,并将hadoopeclipseplugin复制到Eclipse的plugins目录下,可以使用cp ~/下载/hadoopeclipseplugin2.7.1.jar /usr/local/eclipse/plugins/命令完成此步骤。
使插件生效并重启Eclipse:为了让插件生效,需要重启Eclipse,可以通过执行./eclipse clean命令来重启Eclipse,并使插件生效。
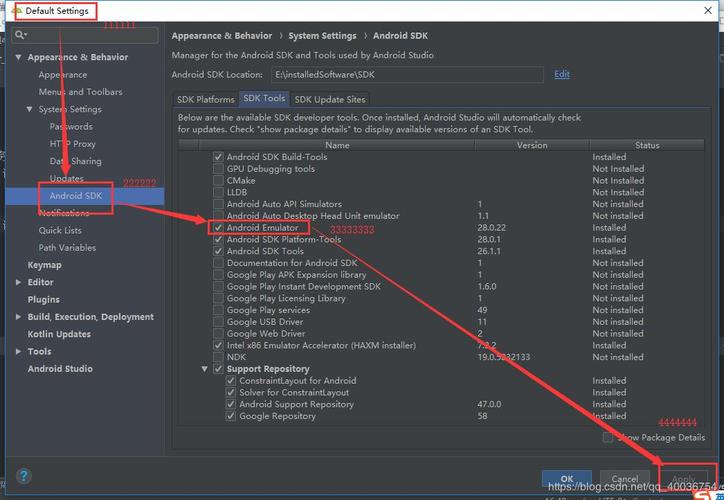
设置Hadoop Map/Reduce:在Eclipse中,进入Window > Preferences菜单,找到Hadoop Map/Reduce选项进行配置,需要指定Hadoop安装位置,例如/usr/local/hadoop。
3、Map/Reduce配置
切换到Map/Reduce视图:在Eclipse中,需要从Java视图切换到Map/Reduce视图,可以通过Window > Perspective > Open Perspective > Other,选择Map/Reduce来实现视角切换。
创建Hadoop位置:在Map/Reduce Locations面板中,单击右键选择New Hadoop Location以创建与Hadoop集群的连接,这里填写的设置应与Hadoop集群的配置相匹配。
高级参数配置:对于高级配置,可能需要填写或验证Hadoop的参数,如fs.defaultFS和hadoop.tmp.dir等,这些参数应与你的Hadoop配置文件(通常位于/usr/local/hadoop/etc/hadoop/)保持一致。
4、创建和测试MapReduce项目
新建MapReduce项目:在Eclipse中,通过点击File > New > Project… > Map/Reduce Project来创建一个新的MapReduce项目,为项目命名,然后完成创建。
创建MapReduce类:在新项目中,创建一个新类用于编写MapReduce代码,可以创建一个名为WordCount的类,并实现相应的map和reduce方法。
编写并运行MapReduce代码:编写好MapReduce代码后,可以在Eclipse中直接运行,并观察输出结果和日志信息,以便调试和优化程序。
在此过程中,可能还需注意以下一些细节:
插件放置问题:有时将插件直接放在plugins目录下可能不生效,可以尝试将插件放在dropins目录下。
环境变量配置:确保所有相关的环境变量都正确配置,包括JAVA_HOME和Hadoop相关的环境变量。
错误处理:如果遇到任何连接或认证错误,检查Hadoop配置文件中的安全设置和用户的权限设置。
还有,在处理大数据时,数据的安全性也是非常重要的一环,要确保数据在处理和传输过程中的安全性,数据的实时处理能力也是衡量一个大数据处理系统的重要指标,需要不断优化系统的处理速度和响应时间。
虽然在Eclipse中配置MapReduce样例工程需要一些详细的步骤,但遵循以上指南可以使过程更加顺利,每个步骤都是为了确保环境的正确配置,以及后续开发工作的顺利进行,无论是插件的准备、Eclipse的配置,还是MapReduce项目的创建和测试,每一步都是构建有效MapReduce应用程序的关键部分。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复