
}

3、创建Reducer类,Reducer类主要负责把Mapper类传过来的数据进行汇总计算 package com.hpe.wc;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
public class Reducera extends Reducer<Text, IntWritable, Text, IntWritable> {
//定义一个写死的常量1
private final static IntWritable result = new IntWritable();
private final static Text word=new Text();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
4、主函数驱动 package com.hpe.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(Mappera.class);
job.setCombinerClass(Reducera.class);
job.setReducerClass(Reducera.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
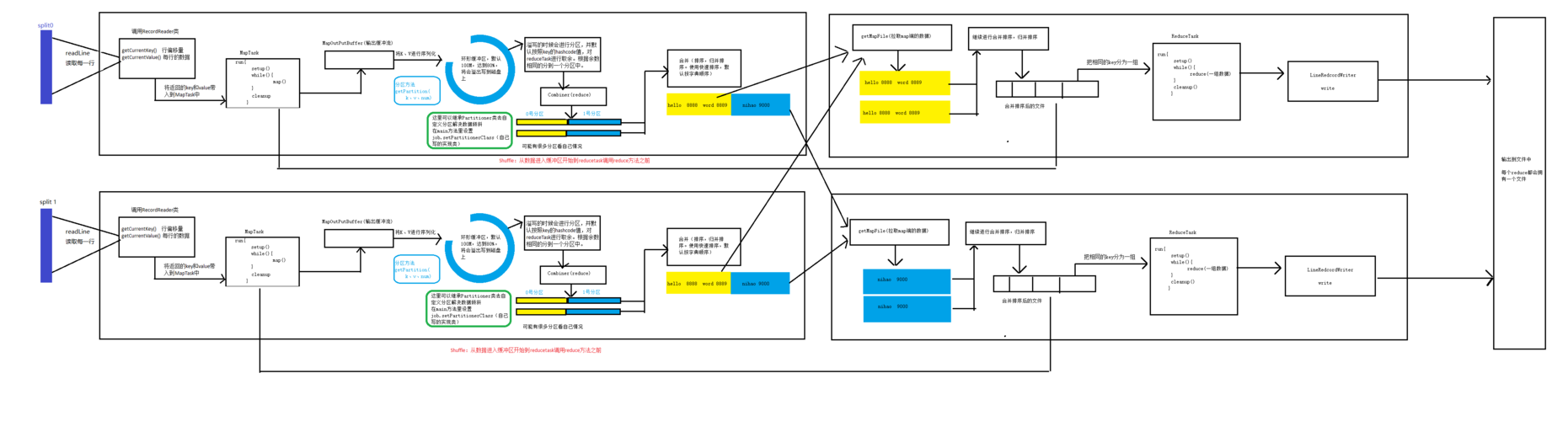
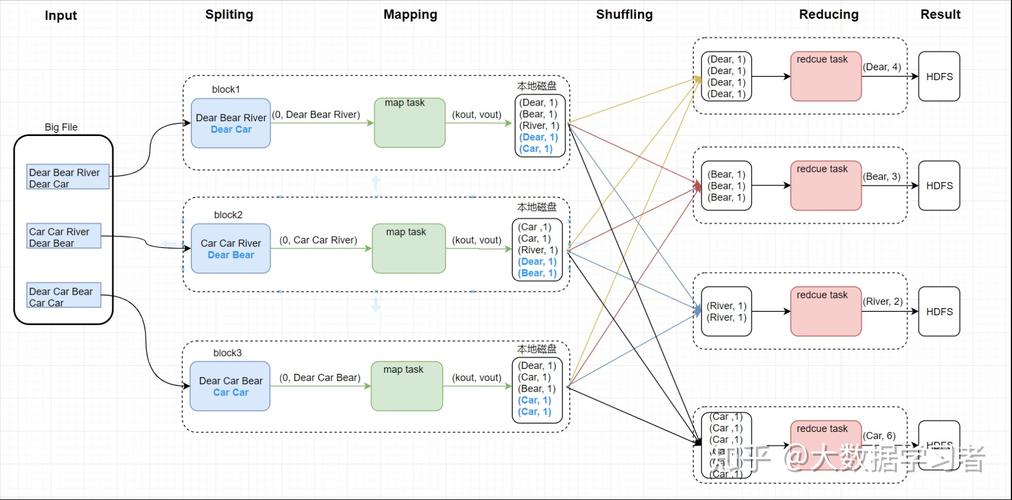
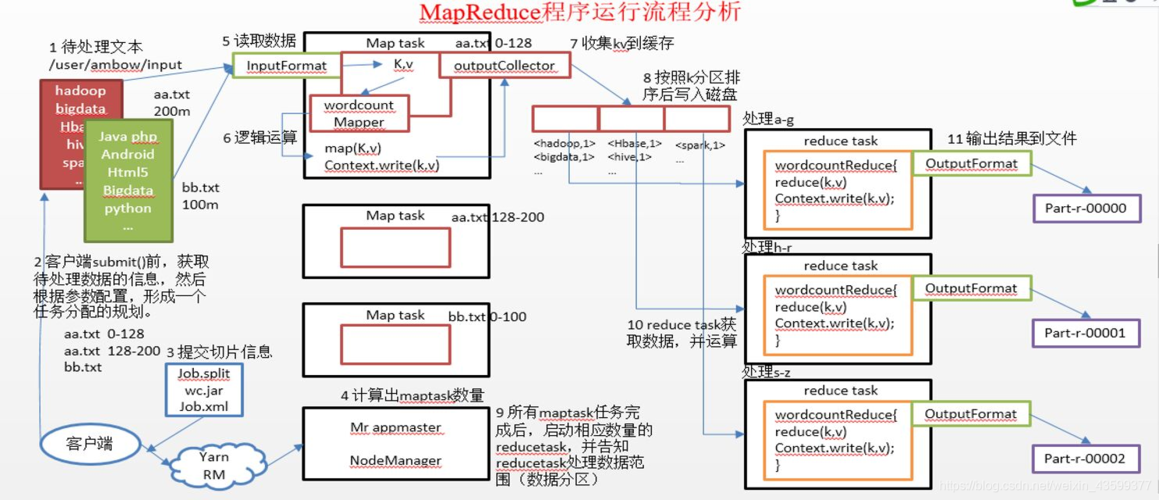
在 Eclipse 下进行 MapReduce 编程是大数据处理中的一个重要环节,本文旨在详细介绍 MapReduce 应用开发的整体流程,并提供具体的实践指导,下面将详细阐述在 Eclipse 下进行 MapReduce 编程的整个流程:
1、环境搭建
安装和配置Hadoop:首先需要在主节点上安装 Hadoop,并进行相应的配置,以确保 Hadoop 集群能够正常运行,这包括设置 Hadoop 的环境变量、配置文件(如 coresite.xml、hdfssite.xml、mapredsite.xml 等),并启动 Hadoop 服务。
安装Eclipse及Hadoop插件:在开发机上安装 Eclipse IDE,并安装 Hadoop 插件以便能够直接操作 HDFS,这一步骤包括下载并安装 hadoop2xeclipseplugin 插件,然后配置插件以连接到 Hadoop 集群。
2、创建MapReduce项目
新建项目:在 Eclipse 中新建一个 Java 项目,用于存放 MapReduce 程序的源代码和资源文件,可以通过 File > New > Map/Reduce Project 快速创建项目,此步骤会导入必要的 Hadoop JAR 包。
配置项目:对项目进行必要的配置,包括指定 Hadoop 的配置目录,确保项目能够找到 Hadoop 相关的库和资源。
3、编写MapReduce程序
编写Mapper类:创建一个继承自 Mapper 的类,重写 map 方法,实现数据的映射处理,Mapper 类的输入是键值对,输出也是键值对。
编写Reducer类:创建一个继承自 Reducer 的类,重写 reduce 方法,实现数据的归约处理,Reducer 类的输入是 Mapper 的输出,经过排序和分组后,输出最终结果。
编写驱动类:创建一个包含 main 方法的类,用于配置和启动 MapReduce 作业,这里需要设置作业的配置参数、输入输出路径、Mapper、Reducer 类等信息。
4、编译和打包
代码编译:在 Eclipse 中对编写的 MapReduce 程序进行编译,确保没有语法错误。
打包成JAR:将编译后的类文件及相关资源打包成一个 JAR 文件,准备提交到 Hadoop 集群运行。
5、运行和调试
运行MapReduce程序:通过 Eclipse 提交 MapReduce 作业到 Hadoop 集群运行,可以观察作业的运行状态,查看日志信息进行调试。
查看结果:作业运行完成后,可以在 HDFS 中查看输出结果,验证程序的正确性。
6、问题排查和优化
监控和日志分析:MapReduce 程序未能按预期运行,需要通过查看 Yarn 上的作业运行日志,分析可能的问题所在。
性能优化:根据作业的运行情况,对 MapReduce 程序进行性能优化,比如调整内存配置、优化数据处理逻辑等。
在实际操作过程中,需要注意以下几点:
环境版本匹配:确保 Eclipse 中的 Hadoop 插件版本与实际 Hadoop 集群版本一致,以避免因版本不匹配导致的问题。
正确配置插件:在 Eclipse 中配置 Hadoop 插件时,需要确保与 Hadoop 集群的配置保持一致,特别是文件系统和 MapReduce 的主节点地址。
合理选择输入输出格式:根据数据处理需求,选择合适的输入格式(如 TextInputFormat)和输出格式(如 TextOutputFormat),以提高程序的兼容性和效率。
通过以上步骤,可以在 Eclipse 环境下高效地进行 MapReduce 应用的开发和调试,这不仅提高了开发效率,也使得开发人员能够更加专注于业务逻辑的实现,而非底层的分布式处理细节。
针对上述内容,提出以下两个相关问题:
1、MapReduce编程中如何处理数据倾斜问题?
处理数据倾斜问题通常有以下几种方法:可以通过在 Mapper 阶段增加额外的逻辑来均匀分配 Key,避免某些 Key 的数据过多;可以使用 Hadoop 的 MapJoin 功能来减少数据传输量;对于极端情况,可以考虑在 Reducer 之前使用 MapSide join 或其他预处理手段来减少数据倾斜的影响。
2、如何优化MapReduce程序的性能?
优化 MapReduce 程序性能可以从多个方面入手:优化数据输入输出格式和存储方式,减少不必要的数据传输和序列化开销;合理设置 Map 和 Reduce 任务的数量,以充分利用集群资源;利用合并(combining)功能减少数据通过网络传输的量;针对特定场景优化算法逻辑,减少不必要的计算和数据读写操作。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复