
MapReduce服务(MRS)是云计算中的一项关键技术,它允许大规模数据集通过分布式计算进行处理,MRS的核心概念源自Google的MapReduce模型,该模型将处理过程分为两个阶段:Map阶段和Reduce阶段。
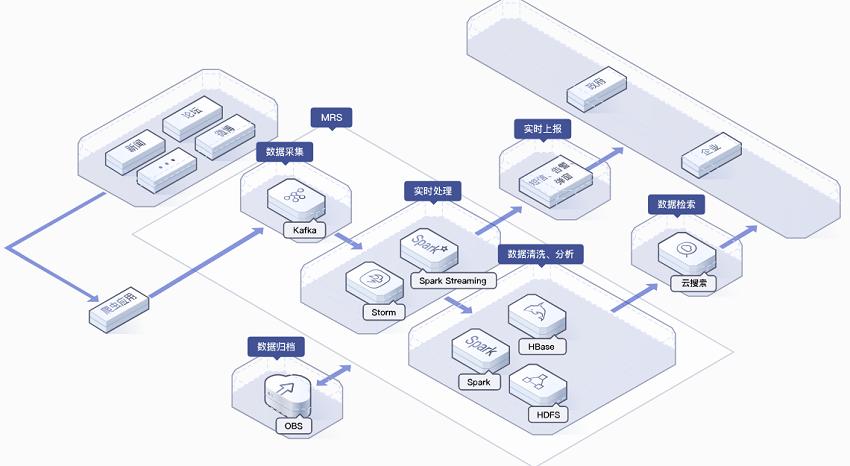

MapReduce服务
MapReduce服务在云平台上为用户提供了一种简化大数据处理的方式,它隐藏了底层复杂的分布式计算细节,使得用户能够轻松地编写处理海量数据的程序,这些程序自动在大量的服务器上并行执行,提高了计算效率和数据处理速度。
核心组件
MapReduce服务通常包含以下几个核心组件:
1、JobTracker: 负责资源管理、任务调度和协调。
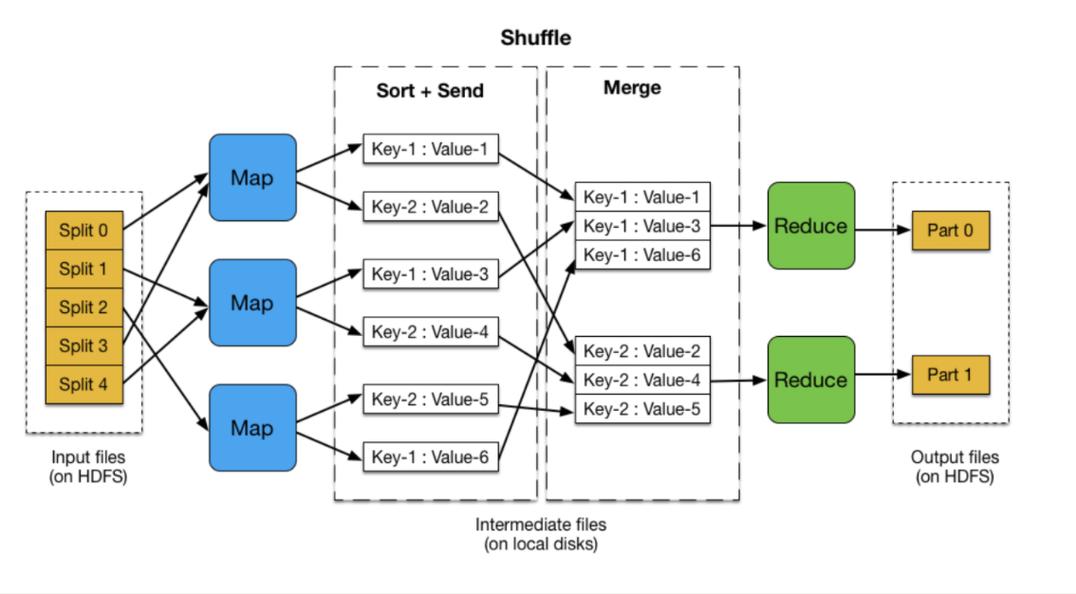
2、TaskTracker: 运行在各个节点上,负责执行具体的Map或Reduce任务。
3、Client: 提交作业到MapReduce系统,并能够跟踪作业的进度。
4、DataNode: 存储输入和输出数据,通常与HDFS(Hadoop Distributed File System)结合使用。
工作原理
Map阶段: 输入数据被分成多个数据块,每个数据块由一个Map任务处理,Map任务将输入数据转换为一组键值对。
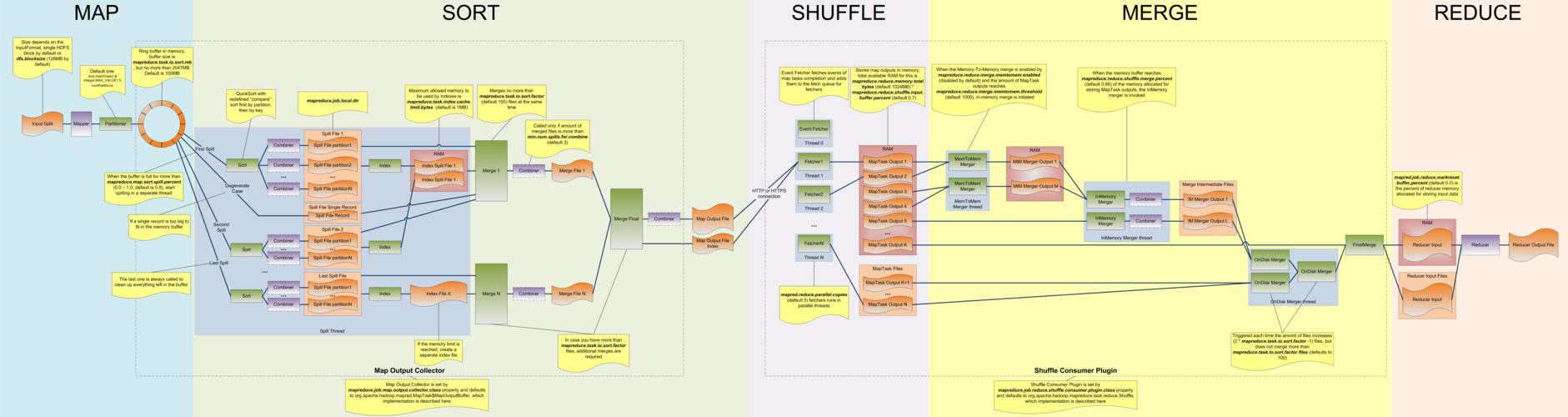
Shuffle阶段: 对Map阶段的输出进行排序和分组,确保具有相同键的所有值都会被发送到同一个Reduce任务。
Reduce阶段: 对每个键的值列表执行用户定义的聚合操作,输出最终结果。
特点与优势
易于编程: 用户只需实现Map和Reduce函数,无需关心并行计算的细节。
扩展性: 可以在数千个计算节点上运行,自动处理硬件故障。
高效: 优化了数据传输和任务调度,减少网络传输开销。
容错性: 能够自动重新执行失败的任务。
应用场景
MapReduce服务适用于多种大数据处理场景,如日志分析、数据挖掘、机器学习等,典型的应用包括:
日志处理: 分析大量日志文件,提取关键信息。
数据转换: 将数据从一种格式转换为另一种格式,例如CSV转JSON。
统计和排序: 对大规模数据集进行统计分析或排序。
相关问题与解答
Q1: MapReduce如何处理数据倾斜问题?
A1: 数据倾斜是指在分布式计算中,某个键对应的数据量远远大于其他键,导致处理该键的任务耗时过长,解决数据倾斜的方法包括:
预分区: 在Map阶段预先对数据进行更细粒度的分区。
Sampling和Range Partitioning: 在Map阶段对数据采样,然后根据采样结果进行范围分区,尽量均匀分配数据。
负载均衡: 在Reduce阶段增加负载均衡机制,动态调整任务分配。
Q2: MapReduce服务在哪些云平台上可用?
A2: MapReduce服务在多个云平台上都有提供,包括但不限于:
Amazon EMR (Elastic MapReduce): 亚马逊提供的托管Hadoop框架服务。
Google Cloud Dataproc: 谷歌提供的快速、易用的、完全管理的 Hadoop 和 Spark 服务。
Azure HDInsight: 微软Azure上的服务,提供Hadoop、Spark等大数据解决方案。
IBM BigInsights on Cloud: IBM提供的基于云的大数据分析平台。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复