
MRS和HDFS

1. 简介
MRS (MapReduce Service) 和 HDFS (Hadoop Distributed File System) 是 Hadoop 生态系统的两个核心组件,Hadoop 是一个开源框架,允许在大量硬件节点上进行分布式处理和存储,它通过将数据和计算任务分散到多个节点上,来处理大规模数据集。
2. HDFS
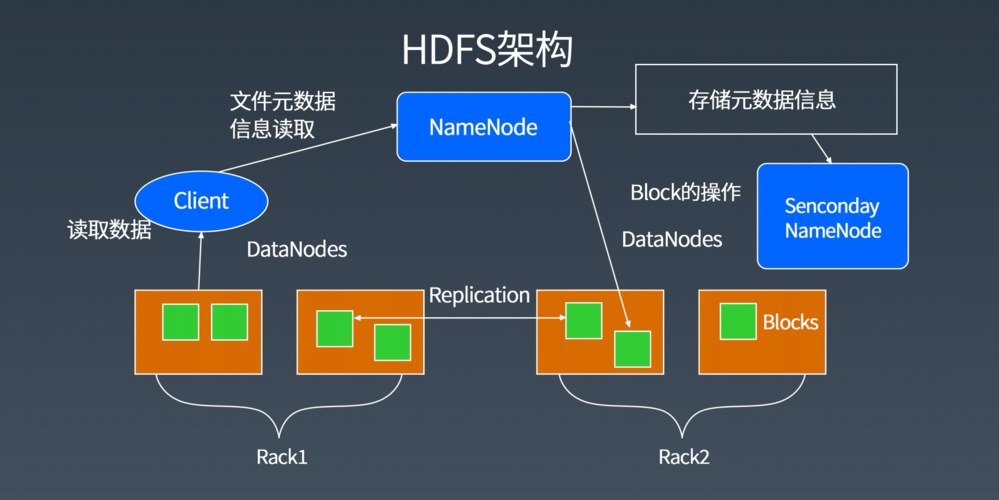
HDFS 是一个高度容错、可扩展的文件系统,适合运行在廉价硬件上,它提供高吞吐量的数据访问,因此非常适合大规模数据集上的应用程序,HDFS 采用主从架构,包括一个 NameNode(主节点)和多个 DataNode(从节点)。
NameNode:负责管理文件系统的命名空间,维护文件和目录的元数据,并协调用户对文件的访问请求。
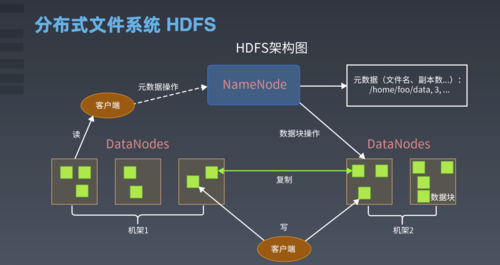
DataNode:存储实际的数据块,并执行由 NameNode 发起的操作,如复制、删除和恢复数据块。
3. MRS
MRS 是基于 Hadoop MapReduce 框架实现的一种服务,用于处理和生成大数据集的相关实现,MapReduce 是一种编程模型,用于并行处理大规模数据集。
Mapper:任务是将输入数据拆分成独立的数据块,并处理这些数据块以生成中间键值对。
Reducer:任务是处理来自不同 Mapper 的中间键值对,并将它们合并成一个结果集。
4. 关系与协作
MRS 和 HDFS 通常一起工作,以提供高效的数据处理能力,HDFS 作为存储层,而 MRS 则作为计算层,当 MRS 执行作业时,它通常从 HDFS 中读取数据,并将处理后的结果写回 HDFS,这种设计使得 MRS 可以有效地扩展到多个节点,从而加快数据处理速度。
5. 应用场景
HDFS:适用于需要存储和管理大量数据的场合,如日志分析、社交媒体数据存储等。
MRS:适合执行数据密集型任务,如日志分析、Web索引、批量数据处理等。
6. 特点对比
| 特性 | HDFS | MRS |
| 角色 | 数据存储 | 数据处理 |
| 架构 | 主从架构 | 主从架构 |
| 容错性 | 高 | 中等 |
| 扩展性 | 强 | 强 |
| 性能 | 高吞吐量 | 高并发处理 |
| 适用场景 | 大数据存储 | 大数据计算 |
7. 相关问题与解答
Q1: HDFS 如何保证数据的可靠性?
A1: HDFS 通过数据块的副本机制来保证数据的可靠性,每个数据块会在不同节点上保存多个副本(默认为3个),即使某个节点发生故障,也能从其他节点上的副本恢复数据。
Q2: MRS 如何处理失败的任务?
A2: MRS 具有失败任务自动重新执行的机制,如果任务在执行过程中失败,系统会将其分配给其他节点重试,直到成功或达到最大尝试次数,MapReduce 框架还会监控任务的进度,并在必要时重新启动失败的任务。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复