
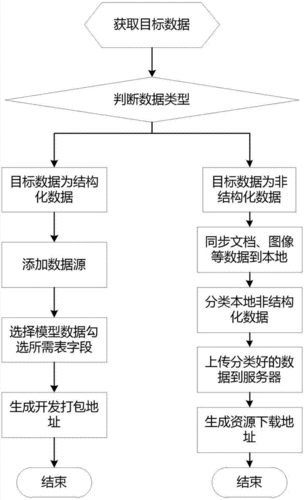
非结构化数据的处理与抽取是现代数据管理中的一项核心任务,特别是在自然语言处理(NLP)领域。

非结构化数据指的是那些没有固定格式或组织模式的数据,如文本、图像、音频和视频等,与之对应的是结构化数据,它们通常以固定的字段和记录形式存储,便于数据库系统进行查询和管理,非结构化数据占据了当今数字世界中数据的绝大部分,并且包含了丰富的信息,这对自动化的信息解析提出了挑战,尤其是在大数据时代,如何有效地从非结构化数据中提取有用信息,成为了一个研究的热点,下面将从几个关键方面来详述非结构化数据的处理方法:
1、数据识别与属性提取:在处理非结构化数据时,一项基本的任务是属性提取,这涉及到识别数据中的有价值信息,并将其分类和索引,文档分析中,可以采用文本挖掘技术来识别作者、日期、主题等元数据,这一过程为数据打下标签,形成元数据,从而使得原本杂乱无章的非结构化数据变得更加有序和可检索。
2、非结构化数据转换:转换非结构化数据为结构化数据是使数据更适合进一步分析的关键步骤,像Unstructured这样的库能够提供内置的数据提取函数,通过这些工具,可以将非结构化数据高效地转换成结构化格式,以便进一步的数据分析,常见的转换包括将文本数据编码为数值向量,或者从图片中提取特征属性。
3、信息抽取技术:信息抽取(IE)是自然语言处理(NLP)的一个核心功能,专注于从非结构化或半结构化数据中识别和提取特定信息,在文本数据中,可以运用各种技术,如命名实体识别(NER)、关系抽取等,来提取出地点、人名、日期或组织结构等信息,随着深度学习技术的发展,基于机器学习的信息抽取方法正在不断取得进展,提高了抽取的准确性和效率。
4、管理和应用工具:对于非结构化数据的管理和应用,有许多工具和技术可供选择,这些工具比如文本编辑器、标签管理系统和内容管理系统(CMS),可以帮助组织、搜索和分享非结构化数据,而一些更高级的数据分析工具,则能够对数据集进行更深层次的分析和洞察发现。
值得一提的是,非结构化数据预处理技术,它涵盖了一系列数据处理的步骤,包括清洗、整合和转换,在进行任何形式的数据分析之前,预处理是确保数据质量的关键步骤,尽管将非结构化数据转换为结构化数据有助于分析,但在某些情况下,保持数据的原始非结构化特性可能更有价值,直接的文本分析能更好地保留上下文和语义信息,根据分析目标的不同,需要灵活选择是否进行数据转换。
非结构化数据的处理和抽取是一个涉及多个技术和步骤的过程,从属性提取到数据转换,再到信息抽取,每一步都至关重要,并依靠当前信息技术的发展,特别是自然语言处理技术的进步,掌握这些技术能够帮助人们更好地管理和利用非结构化数据,增强数据驱动决策的能力和洞察力。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复