
非结构化数据处理技术主要涉及到从各种类型的数据中提取有用信息的过程,这些数据包括文本、图像、音频和视频等,而非结构化抽取是其中的一项关键技术,它旨在将这些杂乱无章的数据转换为结构化信息,以便进一步的分析和应用,具体分析如下:

1、文本挖掘
概念与应用:文本挖掘是从非结构化或半结构化数据中提取有价值信息的技术,特别适用于处理大量的文本数据,如网页、电子邮件、社交媒体帖子等。
文本数据的挑战:文本数据通常具有非结构化和嘈杂的特性,这使得机器学习方法难以直接处理原始文本数据。
2、知识抽取
定义与目标:知识抽取是指从不同来源、不同结构的数据中提取知识,形成结构化数据存入知识图谱。
任务分类:知识抽取涉及多种任务,包括但不限于实体识别、关系抽取、事件抽取等,每种任务都需要特定的技术来实现。
3、事件抽取
事件抽取过程:事件抽取是自然语言处理(NLP)中用于从非结构化或半结构化文本中识别、分类和链接事件的过程。
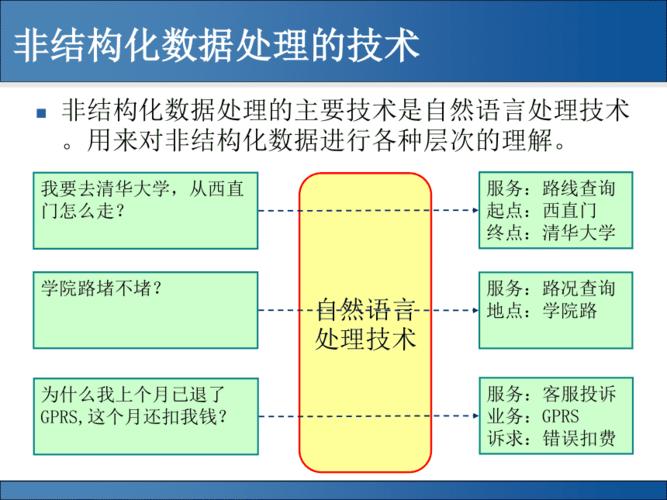
事件触发词:事件通常包括一个动词(事件触发词),以及与该事件相关的参数,如事件发生的时间、地点、参与者等。
4、实体识别与链接
实体的重要性:在非结构化文本中,实体是构建知识图谱的基本元素,如人名、地点、组织等。
实体链接:实体链接涉及将识别出的实体与知识库中的现有实体进行匹配,以便于知识的整合和丰富。
5、关系抽取
定义与目的:关系抽取是指从文本中识别并提取实体之间的语义关系。
挑战与方法:关系抽取的挑战在于如何准确地识别实体间复杂的关系,并采用适当的算法进行处理。
6、情感分析
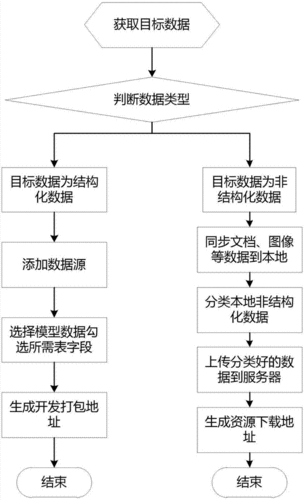
情感分析的应用:情感分析用于判断文本作者对某一主题或产品的情感倾向,广泛应用于市场研究、品牌监控等。
技术手段:情感分析依赖于自然语言处理技术,通过分析词汇的语义和语境来判断情感极性。
7、自然语言理解
技术概述:自然语言理解(NLU)是使计算机能够理解人类语言的技术,它是实现非结构化数据抽取的基础。
应用场景:NLU在聊天机器人、语音助手等应用中发挥着重要作用,它帮助机器准确理解用户的意图和需求。
8、深度学习
深度学习的角色:深度学习在非结构化数据抽取中扮演着重要角色,尤其是在特征自动提取和模式识别方面表现出色。
深度学习模型:卷积神经网络(CNN)、递归神经网络(RNN)等深度学习模型被广泛用于图像和文本数据的处理。
在深入探讨了非结构化数据处理技术的核心内容后,为了获得更全面的了解,还需关注一些相关的知识点和注意事项:
随着技术的不断进步,新的算法和模型正在不断被开发,以提高效率和准确性。
考虑到数据隐私和安全问题,处理非结构化数据时应遵守相关法律法规。
跨领域知识融合可以提升非结构化数据处理的效果,例如结合领域知识和语言学知识。
非结构化数据处理技术是一个广泛而复杂的领域,涵盖了文本挖掘、知识抽取、事件抽取等多种技术,这些技术的共同目标是从庞杂的非结构化数据中提取有价值的信息,并将其转换为结构化数据,以便于进一步的分析和应用,随着人工智能和机器学习技术的发展,非结构化数据处理的能力将不断提升,为各行各业带来更多的洞见和机遇。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复