
在开发基于MapReduce框架的应用时,遵循一系列最佳实践可以确保你的应用程序高效、稳定且易于维护,以下是一些建议和技巧,以帮助你更好地利用MapReduce进行数据处理。

数据预处理与清洗
输入数据格式化:确保输入数据格式统一,避免处理异常数据造成的程序崩溃。
错误容忍:增加对输入数据的容错处理,如跳过无法解析的数据行。
Map函数设计
局部性优化:尽可能在Map阶段完成更多的计算,减少Reduce阶段的负担。
内存使用:注意Map任务的内存使用,避免内存溢出。
Reduce函数设计
并发控制:合理设置Reduce任务的数量,平衡负载和减少执行时间。
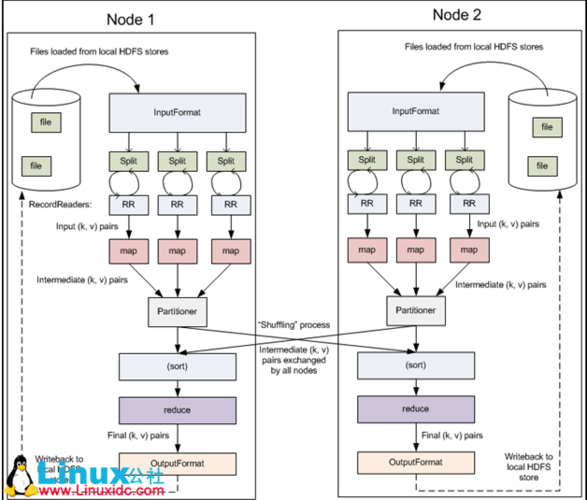
数据聚合:在Reduce阶段进行有效的数据聚合,减少输出数据量。
数据传输与排序
自定义分区:根据应用需求自定义分区策略,优化数据分布。
排序优化:如果可能,减少需要排序的数据量,提升性能。
资源与性能调优
资源分配:根据任务需求合理配置硬件资源,如内存和CPU。
性能监控:监控MapReduce作业的性能指标,及时调整配置。
代码可读性与维护
模块化:将复杂的处理逻辑分解为多个模块,提高代码的可读性和可维护性。
注释与文档:编写清晰的注释和文档,方便团队成员理解和维护代码。
测试与调试
单元测试:编写单元测试用例,确保每个函数按预期工作。
日志记录:添加详细的日志记录,便于问题追踪和调试。
相关问题与解答
1、问: 如何在MapReduce中处理大规模数据集时避免内存溢出?
答: 可以通过调整JVM堆大小、优化数据结构、增加Map和Reduce任务数量来分散内存负载,以及在Map函数中适当地重用对象和批量处理数据来减少内存消耗。
2、问: MapReduce作业运行缓慢,如何诊断和优化性能?
答: 首先检查作业的配置参数是否合理,如Map和Reduce任务的数量;分析作业的日志和性能指标,找出瓶颈所在;考虑优化算法逻辑、数据结构、I/O操作等;确保集群的资源没有被其他低优先级的任务占用。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复