
在当今的机器学习领域,端到端学习已经成为一种越来越流行的范式,特别是在深度学习模型的应用中,端到端学习的核心在于直接从原始数据输入到最终的任务输出,通过模型内部进行所有必须的步骤,包括特征提取和分类或回归等,而无需分阶段手动设计特征提取算法和其他中间步骤,下面将深入探讨端到端学习的各个层面,并分析其在机器学习中的应用情景。
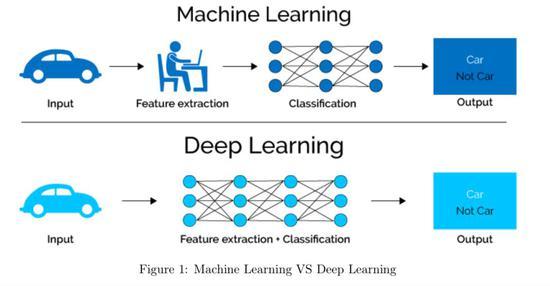

1、端到端学习的定义和特点
定义:端到端学习指的是训练过程中不区分模块或阶段,直接优化任务的总体目标,在这种学习方式下,输入是原始数据,输出是最终任务的结果。
自动化特征提取:模型自行学习如何从原始数据中提取有用的特征,省去了人工设计特征的繁琐过程。
减少人工干预:传统机器学习方法中的许多中间步骤,如特征选取、数据预处理等,在端到端学习中被极大简化或完全由模型自动完成。
2、端到端学习的实现方式
深度学习的应用:利用深度神经网络,尤其是卷积神经网络(CNN)和循环神经网络(RNN),来实现端到端的学习,这些网络能够在处理图像、文本和序列数据方面展现出强大的性能。
数据集和任务匹配:端到端学习需要大量标记好的训练数据,每个输入与其对应的输出目标紧密配对,如图像分类中的图片及其类别标签。
训练过程中的优化:采用适当的损失函数来评估模型的输出与实际目标之间的差异,并使用梯度下降等优化算法来调整网络参数。
3、端到端学习的优势
简化模型开发流程:开发者无需关注过多的中间环节,可以将精力集中在模型结构和训练策略上。
提升模型性能:端到端训练能更好地优化整个系统的性能,减少了分步执行时的信息损失。
适应性强:对于复杂的、难以手工提取特征的任务尤其有效,如语音识别和图像识别。
4、端到端学习的挑战
可解释性差:端到端学习模型往往被视为“黑盒”,难以理解模型内部的特征提取和决策过程。
资源需求高:训练大型神经网络需要大量的计算资源和数据,这可能限制了在某些环境下的应用。
过拟合风险:由于模型复杂度高,若训练数据有限,则存在过拟合的风险,即模型在训练数据上表现优异而在新数据上泛化能力差。
5、机器学习端到端场景实例分析
图像处理领域:在图像识别或对象检测任务中,可以直接输入原始图像到CNN网络中,输出为识别的类别或检测到的对象的位置和类别。
自然语言处理:在机器翻译中,可以使用序列到序列的模型,直接将一段文本从一种语言翻译成另一种语言。
强化学习应用:在自动驾驶汽车中,端到端学习可以用于直接从传感器输入(如视频画面)到控制指令(如方向盘角度)的映射。
针对端到端学习,有必要考虑以下问题以及解答:
如何选择合适的模型架构?
选择模型架构应依据具体任务的需求,比如对于图像任务可以选择CNN,对于序列任务可以选用RNN或Transformer等,考虑模型的复杂度以确保既可以捕捉足够的特征信息又能避免过拟合。
如何处理数据准备和增强?
尽管端到端学习减少了手动特征工程的需要,但数据的准备依然关键,可以通过数据增强技术如旋转、缩放、裁剪等手段来扩充数据集,提高模型的泛化能力。
端到端学习作为一种现代化的机器学习方法,在简化开发流程和提升模型性能方面具有显著优势,尤其是在处理复杂的人工智能任务时表现出色,它也带来了诸如高资源消耗和模型可解释性的问题,在选择应用端到端学习策略时,需综合考虑任务需求、资源条件和数据可用性等因素。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复