
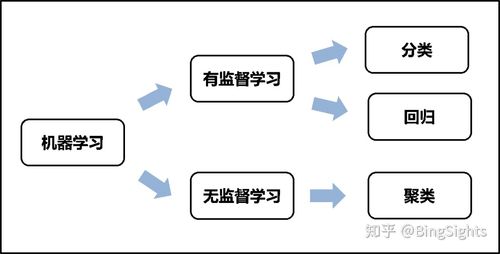
在当今的人工智能领域,机器学习作为一种核心技术,正逐渐改变着我们生活和工作的方式,机器学习大体上可以分为监督学习、非监督学习和半监督学习三大类,非监督学习由于其独特的数据处理方式,在众多场景中展现出巨大的潜力和应用价值,下面将详细探讨非监督学习的端到端场景,并通过具体实例来揭示其工作原理和应用效果:

1、概念理解
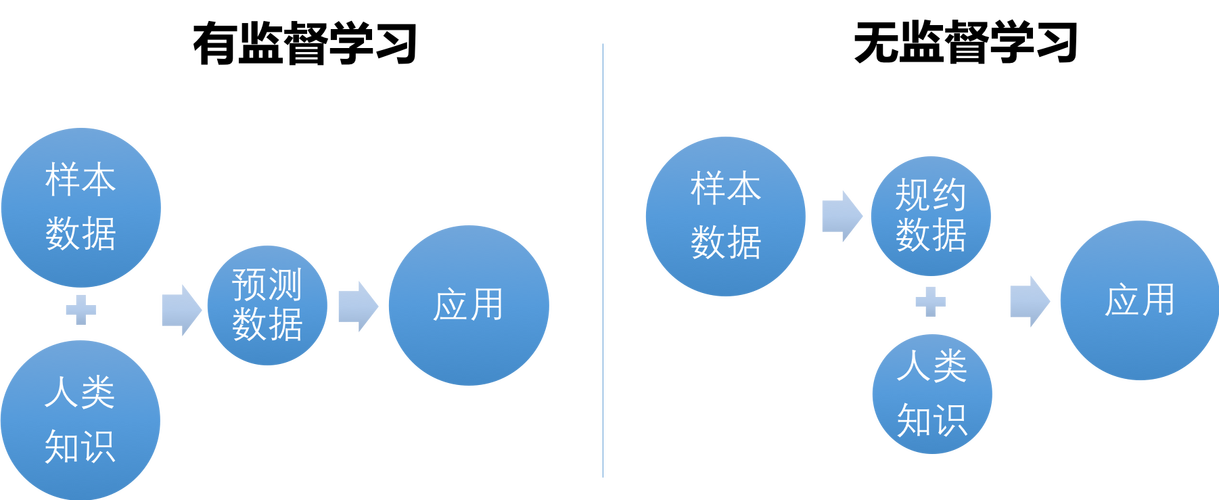
非监督学习是指在训练数据没有标签的情况下,算法自行寻找数据内部的结构和模式,与之相对的监督学习需要标签数据来训练模型,而非监督学习可以自发地发现数据之间的关联性。
端到端的学习则是一种从输入到输出的完整学习过程,不需要人工干预特征提取等步骤,模型自动完成从原始数据到最终目标的转换。
2、端到端学习的优势与挑战
优势在于其简化了模型训练的复杂性,能够自动优化整个系统的参数,减少了人工设计特征提取器的需求。
主要挑战在于需要大量的数据和计算资源,且在某些情况下可能不如专门设计的模型性能优越。
3、端到端非监督学习的关键问题
数据预处理的重要性:在端到端的非监督学习中,由于缺少标签,数据的预处理如去噪、归一化等变得尤为重要,这直接影响到模型能否正确理解数据结构。
模型选择和调优:选择合适的模型并进行细致的参数调优是非监督学习成功的关键,不同的模型和参数组合可能导致截然不同的效果。
4、应用场景分析
聚类:通过端到端的非监督学习,可以实现文本或图像的自动聚类,无需人工标记数据,模型可自行识别并聚集相似特征的数据点。
降维:在处理高维数据时,端到端的非监督学习能自动识别最重要的特征,减少数据的维度而尽量保留有用的信息,用于后续的数据分析或可视化。
5、实际案例
市场细分:使用端到端的非监督学习对客户进行细分,无需预先定义客户类型,模型根据客户的购买行为和偏好自动形成细分市场。
网络安全:在网络安全领域,端到端的非监督学习可以帮助识别异常的网络流量模式,从而及时发现潜在的安全威胁。
针对这些应用,重要的是选择一个合适的模型和算法,确保数据的质量和处理过程的准确性,对于不同行业和问题,可能需要定制化的解决方案来达到最佳效果。
非监督学习的端到端场景展示了一种强大的自动化处理能力,尽管面临数据和资源的挑战,但凭借其在数据模式识别和特征提取方面的独特优势,未来在多个领域内具有广泛的应用前景,随着技术的不断进步和优化,预期这一领域将持续发展,为解决更复杂的问题提供支持。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复