
多因变量机器学习(Multivariate Machine Learning)是一种处理多个输出变量的机器学习方法,在实际应用中,我们经常会遇到需要预测多个目标变量的情况,例如在房价预测问题中,我们可能同时关心房屋的面积、价格和地理位置等因素,在这种情况下,我们需要使用多因变量机器学习方法来建立一个可以同时预测多个目标变量的模型。
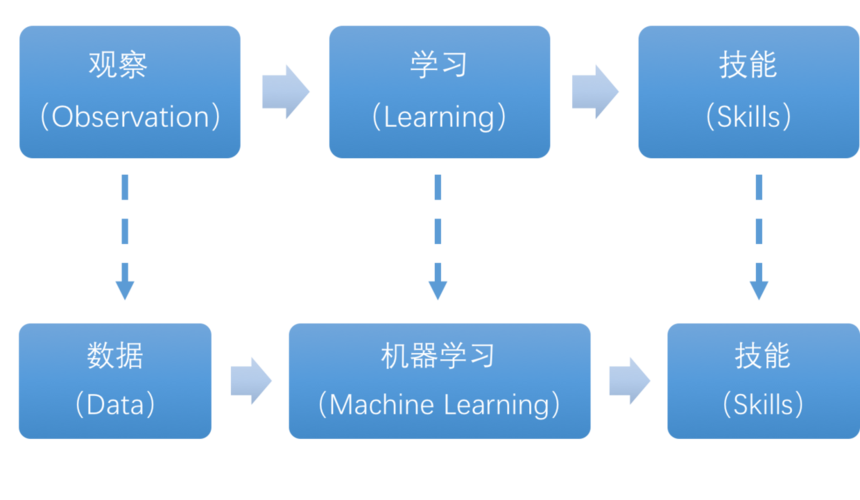

端到端场景(EndtoEnd Scenario)是指在一个完整的机器学习流程中,从数据预处理、特征工程、模型训练到模型评估,所有步骤都在同一个框架内完成,这种场景下,我们可以更加方便地对整个流程进行优化和调整,提高模型的性能。
下面,我们将详细介绍多因变量机器学习在端到端场景中的应用。
1、数据预处理
在多因变量机器学习的端到端场景中,数据预处理是非常重要的一步,我们需要对原始数据进行清洗、缺失值处理、异常值处理等操作,以保证数据的质量和完整性,我们还需要对数据进行标准化、归一化等处理,以消除不同特征之间的量纲影响。
2、特征工程
特征工程是机器学习中非常重要的一环,它可以帮助我们提取出对目标变量有更好预测能力的特征,在多因变量机器学习的端到端场景中,我们可以使用各种特征工程技术来提取特征,
数值特征:对于连续型数值特征,我们可以使用统计方法(如均值、方差等)或者基于树的方法(如随机森林、梯度提升树等)来提取特征。
类别特征:对于离散型类别特征,我们可以使用独热编码、标签编码等方法将其转换为数值特征。
文本特征:对于文本数据,我们可以使用词袋模型、TFIDF等方法提取特征。
图像特征:对于图像数据,我们可以使用卷积神经网络(CNN)等方法提取特征。
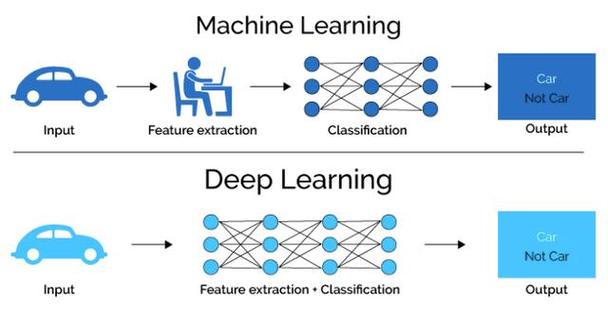
3、模型选择与训练
在多因变量机器学习的端到端场景中,我们需要选择一个合适的模型来同时预测多个目标变量,常用的多因变量机器学习模型有以下几种:
多元线性回归(Multiple Linear Regression):适用于目标变量之间存在线性关系的情况。
支持向量机(Support Vector Machine):适用于目标变量之间存在非线性关系的情况。
随机森林(Random Forest):适用于目标变量之间存在复杂的非线性关系的情况。
神经网络(Neural Network):适用于目标变量之间存在高度非线性关系的情况。
在选择好模型后,我们需要使用训练数据集对模型进行训练,在训练过程中,我们需要不断调整模型的参数,以使模型在训练集上达到最佳的预测效果。
4、模型评估与优化
在模型训练完成后,我们需要使用测试数据集对模型进行评估,以检验模型在未知数据上的预测性能,常用的评估指标包括:
均方误差(Mean Squared Error):用于衡量预测值与真实值之间的平均平方误差。
R²分数(R² Score):用于衡量模型对目标变量的解释能力。
AUCROC曲线:用于衡量模型在不同阈值下的分类性能。
根据评估结果,我们可以对模型进行优化,例如调整模型参数、增加训练数据量、改进特征工程等方法,以提高模型的预测性能。
5、模型部署与应用
在模型优化完成后,我们可以将模型部署到实际应用场景中,以实现对多个目标变量的预测,在实际应用中,我们还需要关注模型的实时性、可扩展性等问题,以确保模型在实际场景中的稳定运行。
多因变量机器学习在端到端场景中的应用涉及到数据预处理、特征工程、模型选择与训练、模型评估与优化以及模型部署与应用等多个环节,通过这些环节的协同工作,我们可以建立一个可以同时预测多个目标变量的高效、准确的机器学习模型。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复