
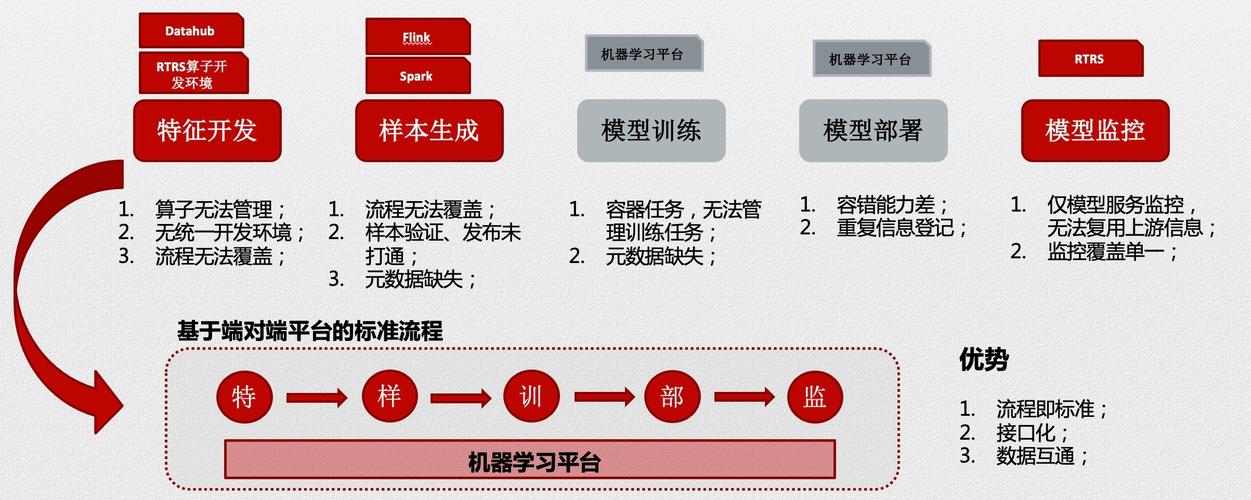
在当今时代,机器学习正逐渐渗透到商业决策的各个方面,特别是在产品定价系统中,利用机器学习算法来优化和自动化定价策略已成为企业增强竞争力的关键手段之一,下面将详细介绍一个端到端的机器学习定价系统场景,并探讨其关键组成部分:

1、数据预处理
数据采集:需要收集与产品定价相关的各类数据,包括但不限于市场数据、竞争对手定价策略、客户行为数据等。
数据清洗:对采集的数据进行清洗,剔除无关或错误的数据点,保证数据的质量。
特征工程:通过选择、提取和构造影响产品定价的关键特征,为模型训练打下基础。
2、模型选择与训练
选择合适的算法:根据业务需求和数据特性,选择最合适的机器学习算法,如决策树、随机森林或深度学习等。
模型训练:使用已处理的数据对选定的模型进行训练,调整参数直到达到最优性能。
交叉验证:通过交叉验证方法评估模型的泛化能力,避免过拟合问题。
3、模型评估与优化
性能评估:采用适当的评估指标,如准确率、召回率、F1分数等,全面评价模型性能。
模型优化:根据评估结果进一步优化模型,可能包括调整模型结构、优化算法或重新进行特征选择。
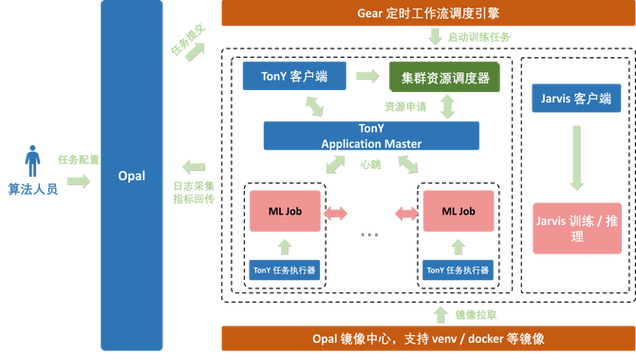
4、部署与监控
模型部署:将训练好的模型部署到生产环境中,集成到定价系统中去。
实时监控:监控模型在实际运行中的表现,确保其稳定性和准确性。
定期更新:随着市场变化和数据积累,定期对模型进行更新和优化以维持其有效性。
5、分析与报告
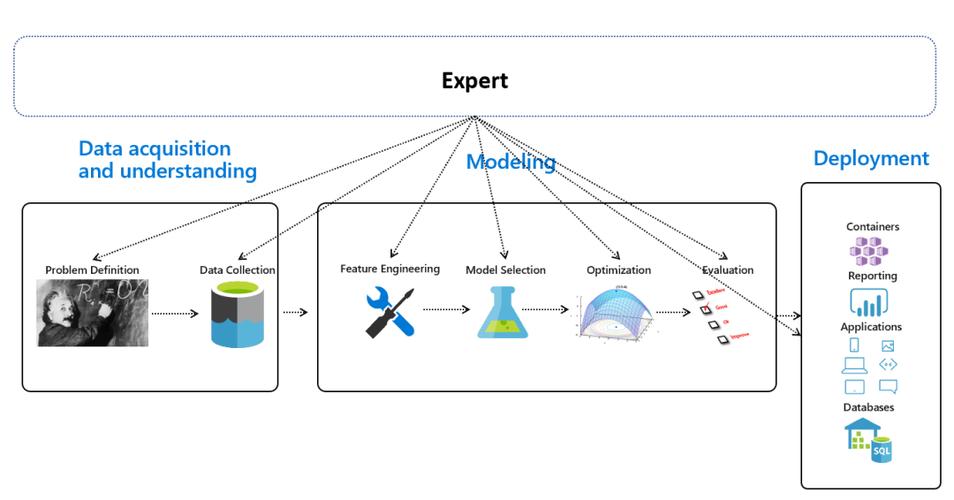
结果分析:分析模型输出的定价策略与实际效果,评估其商业影响。
报告生成:制作详细的分析报告和图表,为企业决策提供直观的依据。
在构建机器学习定价系统的过程中,还需要注意以下问题:
数据的实时性和准确性对模型性能至关重要。
特征工程是提高模型预测能力的关键步骤,需要深入理解业务和数据。
模型的选择和优化是一个迭代过程,需要不断试验和调整。
可以看到机器学习在产品定价系统中的端到端应用涉及多个环节,从数据预处理到模型部署及后续的监控和优化,每一步都对最终的定价策略有着直接的影响,成功的机器学习定价系统能够为企业带来更准确、更灵活的定价策略,从而在激烈的市场竞争中脱颖而出。
相关问题与解答
Q1: 如何处理机器学习定价系统中的数据不平衡问题?
A1: 可以采用重采样技术,对少数类样本进行过采样或对多数类样本进行欠采样,另外也可以使用合成数据生成方法(如SMOTE)来增加样本多样性。
Q2: 在模型部署后,如何持续提升模型性能?
A2: 持续收集新数据并反馈到模型训练中,同时监控模型表现并根据业务变化适时调整模型参数或进行再训练。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复