
1、核心模块
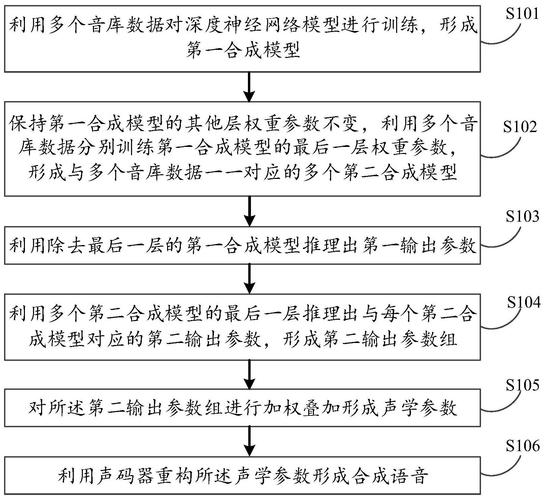

文本分析: 文本分析主要是将输入的文字转换成机器可以理解的音素或者字符号序列,这一步骤是语音合成的基础。
声学模型: 声学模型根据文本分析的结果预测声音的声学特征,如基频、谱包络等,是语音生成准确度的保证。
声码器: 声码器负责将声学模型输出的声学特征转换为实际的语音波形,其质量直接影响到最终声音的自然度和清晰度。
完全端到端模型: 这种模型直接从文本到语音波形的映射,简化了传统流程中的多个独立模块,提高了系统的整体效率和性能。
2、进阶主题
快速语音合成: 针对实时或近实时的应用需求,优化模型和算法以减少合成时间,提高响应速度。
低资源语音合成: 在有限的数据资源下,通过算法优化和模型结构调整实现高效准确的语音合成。
鲁棒语音合成: 增强模型对噪声和异常值的处理能力,确保在不同环境下都能生成稳定清晰的语音。
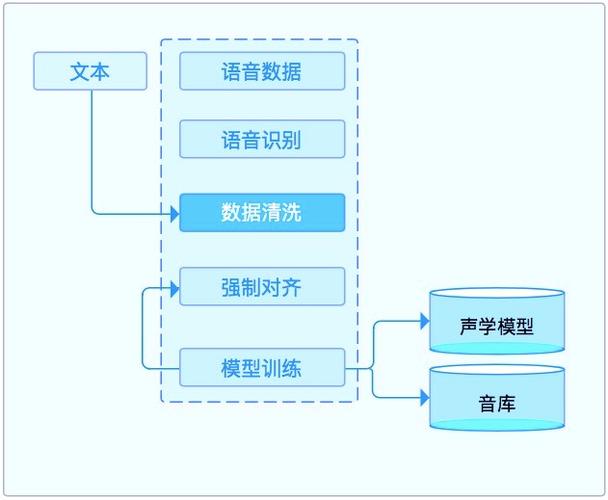
富有表现力的语音合成: 通过模拟不同的情感和语调,使合成的语音更加自然和具有感染力。
可适配语音合成: 根据不同用户的特定需求定制语音合成效果,如音色、语速等。
3、应用领域
在线教育: 提供语言学习、阅读辅助等功能,帮助视障人士或学习障碍者获取知识。
语音助手: 在智能家居、移动设备中提供自然流畅的交互体验。
广告配音: 自动化生成广告旁白,提高效率和降低成本。
4、技术挑战与解决方案
面对多语种、多音色的需求,如何训练一个通用且高效的模型。
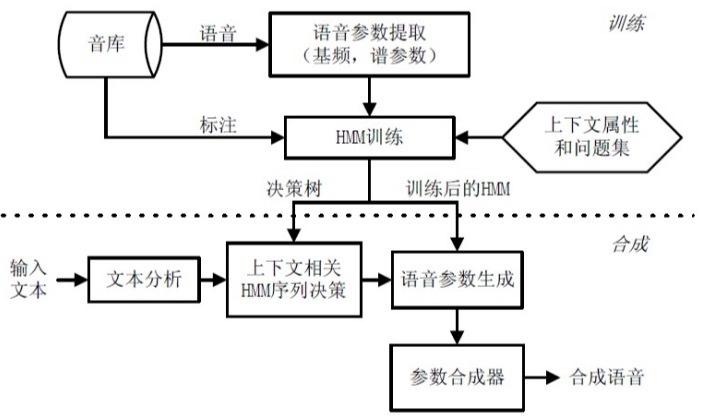
对于实时性要求高的应用,如何优化模型以减少延迟。
在资源受限的环境中,如何保持高质量的语音输出。
5、未来发展趋势
个性化语音合成: 随着技术的发展,用户期待能有更多的个性化设置,如定制音色、语速等。
跨语言合成能力: 提高模型对不同语言的适应能力和准确度。
【相关问题与解答】
1、问: 多音色语音合成技术在实际应用中有哪些挑战?
答: 主要挑战包括高质量音色的再现、各种语言和口音的准确性、以及在低资源环境下的性能维持,隐私和伦理问题也是需要考虑的重要因素。
2、问: 未来多音色语音合成技术的发展方向是什么?
答: 未来的发展方向可能包括更深层次的情感和语调控制、更强大的个性化定制功能,以及更好的跨语言合成能力,提升模型的效率和降低对硬件资源的需求也是重要的研究方向。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复