
在大数据时代,处理模式和微调大模型是两个重要的任务,这些任务需要大量的数据,并且对数据有一些特定的要求,下面将详细探讨这些要求。
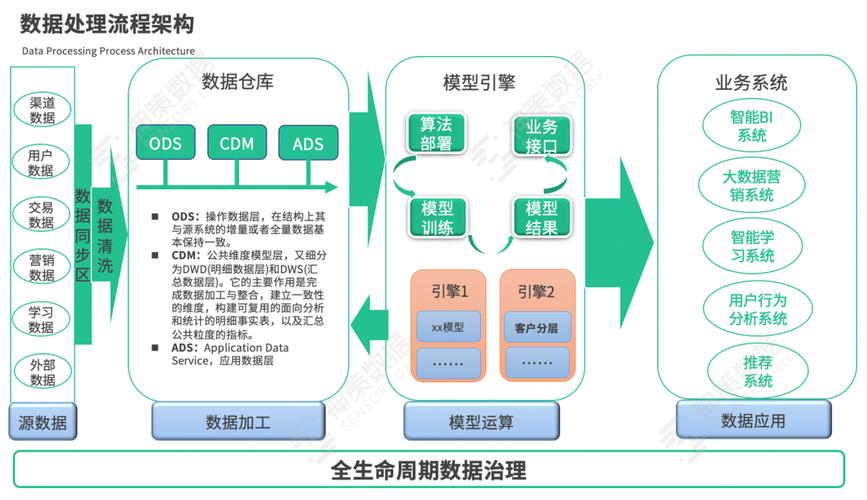

大数据处理模式的数据要求
在大数据处理中,模式通常指的是数据的组织形式和结构,处理模式时,数据需要满足以下要求:
1、完整性: 数据必须是完整的,没有缺失值或错误,以确保分析的准确性。
2、准确性: 数据应当准确反映现实世界的情况,避免误导性的分析结果。
3、一致性: 数据的格式应该一致,以便于处理和分析。
4、可访问性: 数据需要能够被轻松访问和检索,支持高效的数据处理。
5、时效性: 数据应当是最新的,以反映当前的趋势和模式。
6、相关性: 数据需要与分析目标相关,避免无关数据的干扰。
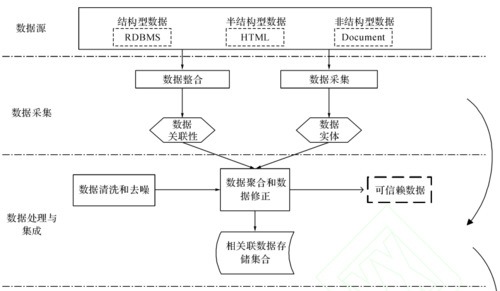
7、多样性: 数据集应该包含多种类型的数据,以提供更全面的视角。
8、规模: 对于大数据分析,数据量通常需要足够大,以便发现统计上显著的模式。
大模型微调的数据要求
大模型微调是指对预训练的大型机器学习模型进行细微调整以适应特定任务的过程,这个过程对数据有以下要求:
1、标注质量: 微调数据需要有高质量的标注,因为模型的性能很大程度上取决于训练数据的标注准确性。
2、代表性: 数据应代表模型将要部署的实际场景,包括各种边缘情况。
3、多样性: 数据集应包含多样化的样本,以避免过拟合。
4、平衡性: 如果任务涉及多个类别,数据应该是平衡的,避免模型对某些类别的偏见。
5、规模: 虽然不需要像完整训练数据集那么大,但微调数据集应该足够大,以便模型学习到足够的信息。
6、清洗和预处理: 数据应该经过适当的清洗和预处理,以提高模型训练的效率和效果。
相关问题与解答
q1: 微调大模型时,如果数据量不足怎么办?
a1: 如果数据量不足,可以考虑以下几种策略:
1、使用数据增强技术来扩充数据集。
2、利用迁移学习,从一个相关的大型数据集开始微调。
3、采用半监督学习方法,结合少量标注数据和大量未标注数据进行训练。
4、选择更适合小数据集的模型架构或正则化技术。
q2: 如何处理大数据处理中的缺失值问题?
a2: 处理缺失值可以采取以下几种方法:
1、删除含有缺失值的记录(列表删除)。
2、填充缺失值,可以使用均值、中位数、众数或基于模型的预测值。
3、使用插补方法,如多重插补,来估计缺失值的可能值。
4、在模型训练过程中考虑缺失值,使用能够处理缺失数据的算法。
5、如果缺失值不是随机的,可能需要更复杂的统计方法来处理。
在处理大数据模式和微调大模型时,确保数据的质量和适用性是至关重要的,通过遵循上述要求和策略,可以提高分析的准确性和模型的性能。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复