
大数据与大容量数据库概述

定义和概念
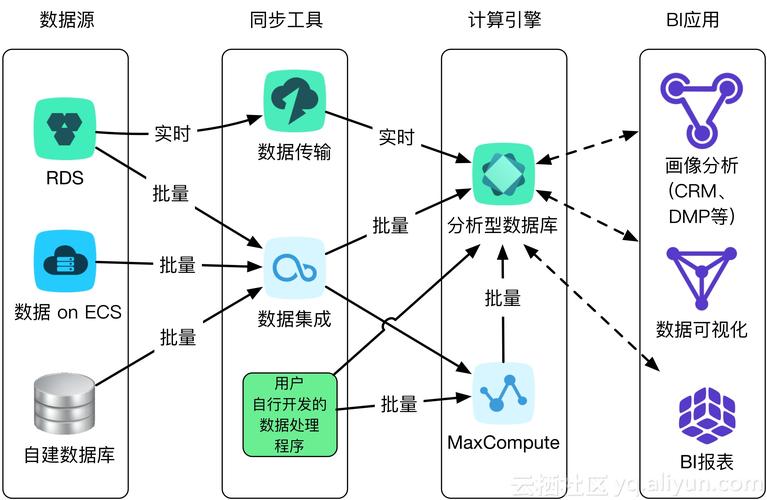
大数据:指的是数据量巨大,传统数据处理软件无法有效处理的数据集合,它通常具有三个主要特征:大量性(Volume)、高速性(Velocity)和多样性(Variety)。
大容量数据库:是指可以存储和处理大规模数据集的数据库系统,它们通常具备高并发访问、高效存储和快速查询等特点。
技术架构
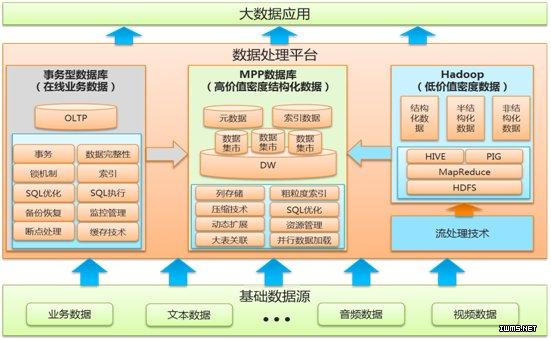
分布式系统:大数据处理通常依赖于分布式计算框架,如Hadoop和Spark,这些框架能够在多台计算机上并行处理数据。
NoSQL数据库:与传统的关系型数据库不同,NoSQL数据库在设计上更加注重水平扩展性和非结构化数据的处理能力,例如MongoDB、Cassandra和DynamoDB等。
应用场景
互联网搜索:搜索引擎需要处理海量的网页信息和用户查询请求。
金融交易分析:金融机构需要实时分析交易数据,以识别市场趋势和欺诈行为。
社交媒体分析:社交平台需存储和分析用户的交互数据,以提供个性化的内容推荐。
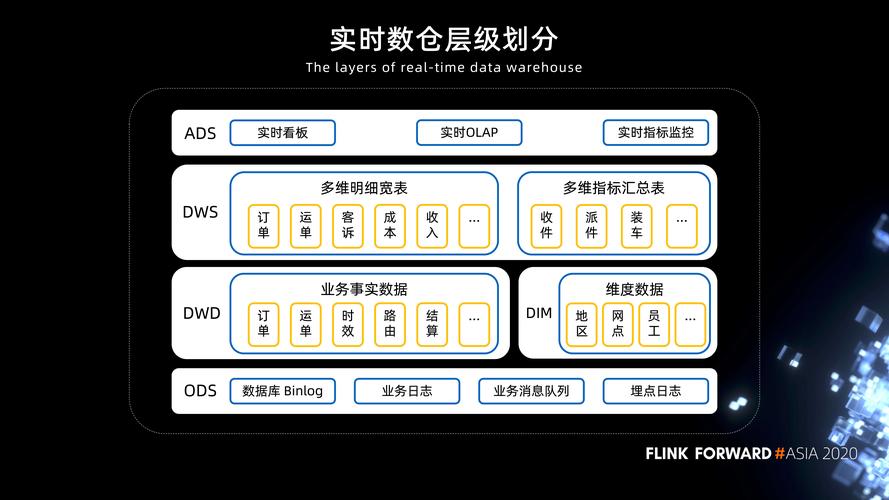
关键技术与挑战
数据存储
分布式文件系统:如HDFS,它允许跨多个物理服务器存储大量数据,并提供高容错性。
列式存储:相对于行式存储,列式存储优化了读操作,适合做大量数据聚合操作的场景。
数据处理
批处理与流处理:批处理适用于不需即时响应的场景,而流处理则针对实时数据分析。
数据索引与查询优化:为了提高查询效率,大容量数据库需要高效的索引结构和查询优化算法。
数据安全与隐私
加密技术:对敏感数据进行加密,保护数据在传输和存储过程中的安全。
访问控制:确保只有授权用户才能访问特定的数据资源。
相关问题与解答
Q1: 大数据处理中常见的性能瓶颈有哪些?
A1: 大数据处理中的性能瓶颈主要包括I/O瓶颈、网络瓶颈、CPU计算瓶颈和内存瓶颈,I/O瓶颈通常发生在数据读写过程中;网络瓶颈是由于数据传输造成的延迟;CPU计算瓶颈是因为数据处理任务复杂导致的计算资源不足;内存瓶颈则是由于数据量过大,超出了内存容量的限制。
Q2: 如何选择合适的大容量数据库?
A2: 选择合适的大容量数据库时需要考虑以下因素:数据模型(关系型或非关系型)、数据一致性需求、可扩展性、性能要求、成本预算以及技术支持,如果应用需要事务支持和强一致性,则可能更适合使用传统的关系型数据库;而对于需要快速读写、高可扩展性的应用场景,则NoSQL数据库可能是更好的选择。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复