
大数据技术通过优化现有数据库、采用分布式数据库和NoSQL数据库等方法解决大容量数据库的问题。
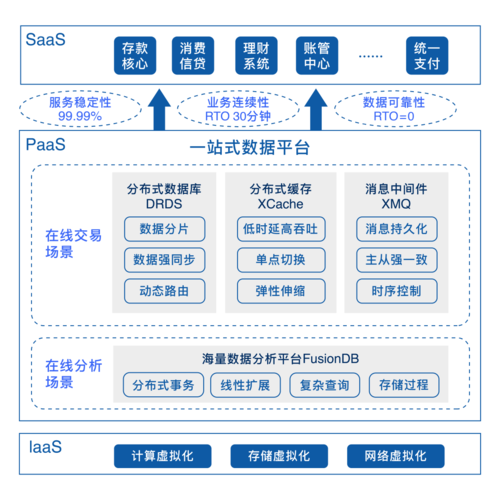

在面对超大规模数据集时,传统的关系型数据库常常遇到性能瓶颈,为了解决这一问题,可以采取几种不同的策略,对传统数据库如MySQL进行优化是一种成本较低且不需要修改现有业务代码的方法,但其存在优化瓶颈,数据量过亿时可能无法继续支撑相应业务,升级数据库类型,选择100%兼容MySQL的数据库产品可以在不影响现有业务的前提下提升数据库性能,不过这需要更多的资金投入,可以从根本上选择一步到位的大数据解决方案,更换为NewSQL或NoSQL数据库,虽然需要修改源程序代码,但扩展性强且成本低,没有数据容量瓶颈。
从数据库设计和表创建时就考虑性能,是应对大容量数据库问题的重要步骤,MySQL数据库本身高度灵活,但这也导致其性能严重依赖开发人员的能力,设计表时应避免NULL值出现,尽量使用更小的数据类型如INT而非BIGINT,用整型存储IP地址等,在查询优化方面,应尽量减少对数据库的访问次数和结果集行数,合理使用索引,并避免全表扫描。
ShardingJDBC是一款基于Java的轻量级分布式数据库解决方案,它通过分库分表、读写分离等技术手段有效提升数据库性能,通过将大表拆分成多个小表,降低单表数据量,减少锁的竞争,提高并发处理能力,ShardingJDBC还支持读写分离,将读操作分发到从库上,分散数据库负载,提高系统吞吐量和稳定性。
解决大容量数据库问题的关键在于根据具体的业务需求和技术条件,选择合适的数据库类型和技术方案,无论是优化现有数据库、切换到分布式数据库还是采用NoSQL数据库,每种方法都有其适用场景和优缺点。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复