
分布式数据库方案_方案
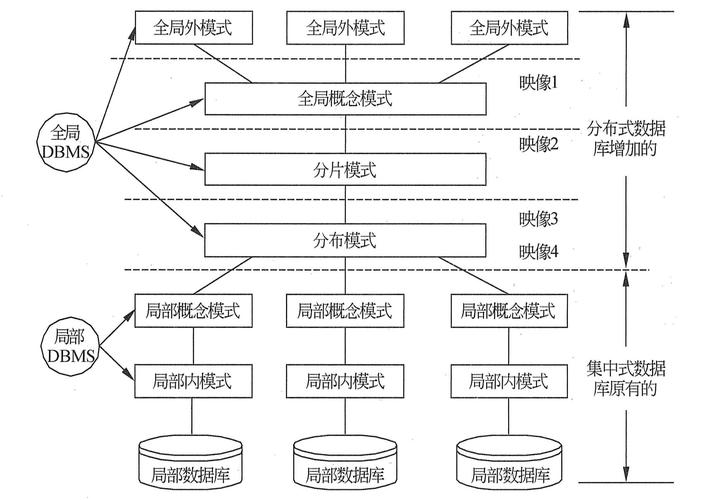

概述
在当今数据驱动的时代,传统的集中式数据库系统已无法满足日益增长的数据存储和处理需求,分布式数据库通过将数据分散在多个节点上,不仅提高了系统的可扩展性和容错能力,还能有效地提升数据处理速度,本方案旨在提供一个详细的分布式数据库解决方案,包括设计原则、架构选择、关键技术及实施步骤。
设计原则
1、可扩展性:系统应能轻松增加更多节点以应对数据增长。
2、高可用性:确保数据始终可访问,即使在部分节点失效时。
3、一致性与分区容忍性:根据CAP理论,合理平衡一致性和分区容忍性。
4、性能优化:确保查询和事务处理的高效率。
5、安全性:保障数据的安全性和隐私。
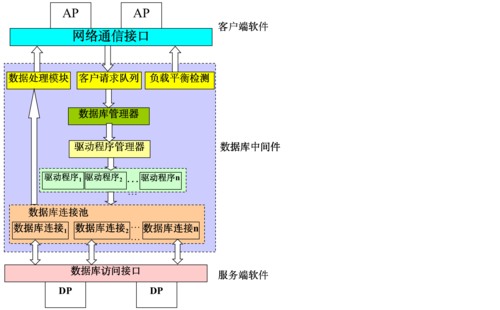
架构选择
数据库模型
NoSQL vs. SQL:根据应用需求选择适合的数据模型,如文档存储、键值存储等。
数据分布策略
哈希分布:通过哈希函数将数据均匀分布在各个节点。
范围分布:按照数据范围将数据分配到特定节点。
目录分布:使用全局目录来管理数据的分布。
复制策略
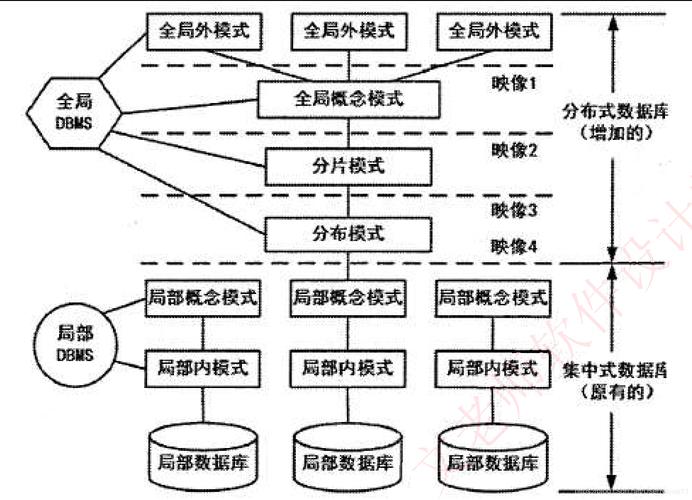
主从复制:一主多从,主节点处理写操作,从节点处理读操作。
多主复制:多个主节点,每个节点都可以处理读写操作。
关键技术
分布式事务处理:保证跨节点操作的原子性。
数据同步技术:确保各节点间数据的一致性。
分布式查询优化:优化跨节点查询的性能。
负载均衡:动态调整数据和请求的分布以优化性能。
实施步骤
1、需求分析:明确业务需求和预期目标。
2、技术选型:根据需求选择合适的数据库类型和技术栈。
3、架构设计:设计合理的系统架构和数据分布策略。
4、环境搭建:配置硬件环境和网络设置。
5、系统开发:编写或集成分布式数据库系统。
6、测试验证:进行系统测试,包括压力测试和故障模拟。
7、部署上线:将系统部署到生产环境并监控其运行状态。
8、维护与优化:根据运行情况进行调整和优化。
单元表格
| 组件 | 功能 | 技术选型 |
| 数据库模型 | 存储数据结构 | NoSQL/SQL |
| 数据分布 | 数据在节点间的分布 | 哈希/范围/目录 |
| 数据复制 | 数据的备份与同步 | 主从复制/多主复制 |
| 事务处理 | 保证操作的原子性 | 两阶段提交/补偿事务 |
| 查询优化 | 提高查询效率 | 查询规划/索引优化 |
| 负载均衡 | 请求和数据的动态分配 | 软件负载均衡/硬件负载均衡 |
通过以上步骤和技术选型,可以构建一个高效、可靠且易于扩展的分布式数据库系统,实施过程中可能会遇到各种挑战,如数据一致性维护、系统监控和调优等,持续的技术跟进和系统评估是必不可少的。
Q&A
Q1: 分布式数据库中的CAP定理是什么?
A1: CAP定理指出,在一个分布式数据存储系统中,Consistency(一致性)、Availability(可用性)、Partition Tolerance(分区容忍性)三者不可兼得,最多只能同时满足其中两项。
Q2: 如何保证分布式数据库中的事务一致性?
A2: 可以通过两阶段提交协议、补偿事务或者利用分布式事务协调器等方法来保证分布式数据库中的事务一致性。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!

发表回复