
分布式数据库读写分离是一种常见的数据库优化策略,旨在通过将读操作和写操作分散到不同的服务器上,来提高系统的整体性能和可用性,这种分离通常涉及主从复制架构,其中一个或多个服务器(主节点)处理写请求,而其他服务器(从节点)处理读请求。
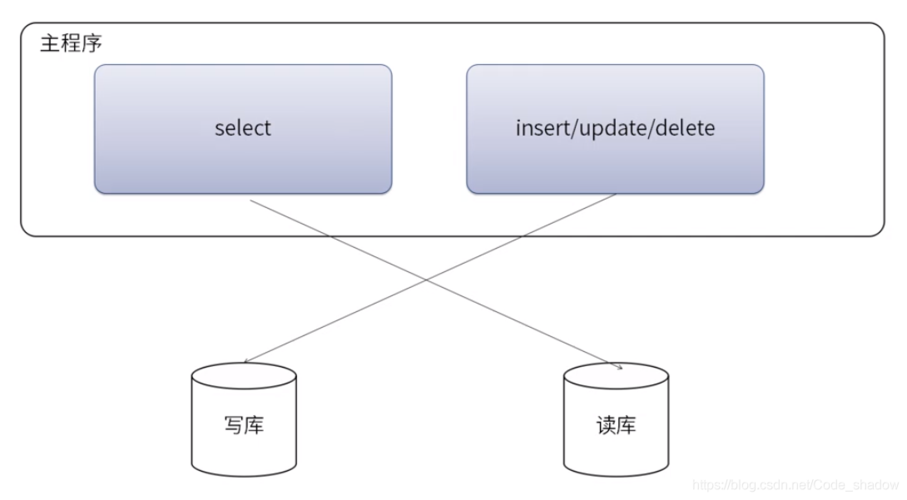

开启读写分离的步骤
1、准备环境:确保你拥有足够的服务器资源,至少需要一个主节点负责写操作,以及一个或多个从节点用于读操作。
2、配置主节点:设置主数据库服务器以接受写请求,并配置它以复制数据到从节点,这可能涉及修改配置文件,启用二进制日志等。
3、配置从节点:在每个从数据库服务器上配置复制客户端,使其连接到主节点并接收数据更新。
4、启动复制:先在主节点上锁定数据库,导出数据快照,然后将此快照导入到从节点,解锁主节点上的数据库,并开始复制过程。
5、分配读写负载:在应用程序层面实现逻辑,使得所有的写请求被路由到主节点,而所有的读请求被分散到从节点。
6、监控和维护:持续监控复制状态、性能指标和节点健康,及时处理可能出现的问题。
读写分离的优势
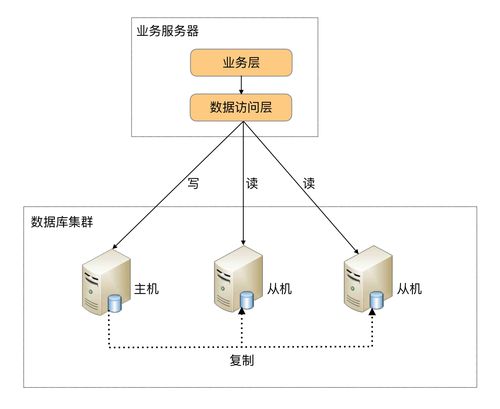
性能提升:由于读写操作被分离,每个服务器可以专注于其核心任务,从而减少资源竞争。
可扩展性增强:可以根据读或写的需要独立地增加更多的读节点或写节点。
高可用性:即使主节点出现问题,从节点仍可提供读服务,保障了系统的持续可用性。
负载均衡:可以通过负载均衡器将读请求分发到不同的从节点,进一步优化性能。
注意事项
数据一致性:读写分离可能会导致主从节点之间的数据存在短暂的不一致情况。
复制延迟:网络延迟和处理能力差异可能导致从节点的数据与主节点不同步。
事务管理:复杂的事务可能需要在主节点上执行以保证一致性。
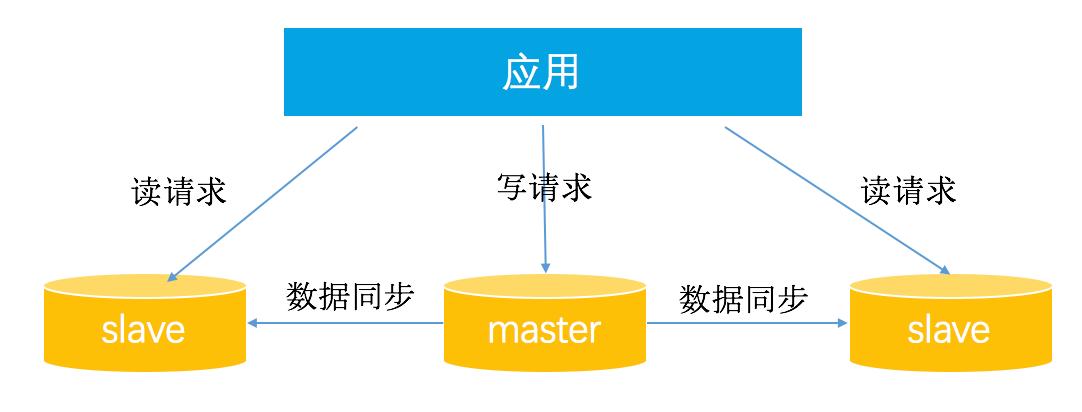
相关配置示例
以下是一个简化的MySQL主从复制配置示例:
在主节点上: CHANGE MASTER TO MASTER_HOST='从节点IP', MASTER_USER='复制用户', MASTER_PASSWORD='密码', MASTER_LOG_FILE='日志文件名', MASTER_LOG_POS=日志位置; START SLAVE; 在从节点上: CHANGE MASTER TO MASTER_HOST='主节点IP', MASTER_USER='复制用户', MASTER_PASSWORD='密码', MASTER_LOG_FILE='日志文件名', MASTER_LOG_POS=日志位置; START SLAVE;
问题与解答
Q1: 在读写分离架构中,如果主节点宕机怎么办?
A1: 如果主节点宕机,写操作会受到影响直到主节点恢复,对于读操作,可以立即切换到一个健康的从节点,为了提高可用性,可以配置多个主节点并使用自动故障转移机制,以确保一个主节点宕机后,另一个可以接管写操作。
Q2: 如何处理读写分离中的复制延迟问题?
A2: 复制延迟是正常现象,特别是在高负载情况下,要处理这个问题,可以在应用程序层面实施“读己所写”(readyourwrites)的模式,即在写入后的一段时间内,直接从主节点读取数据;或者采用半同步复制来减少延迟,还可以优化网络和提高服务器性能来降低延迟。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复