
数据存储
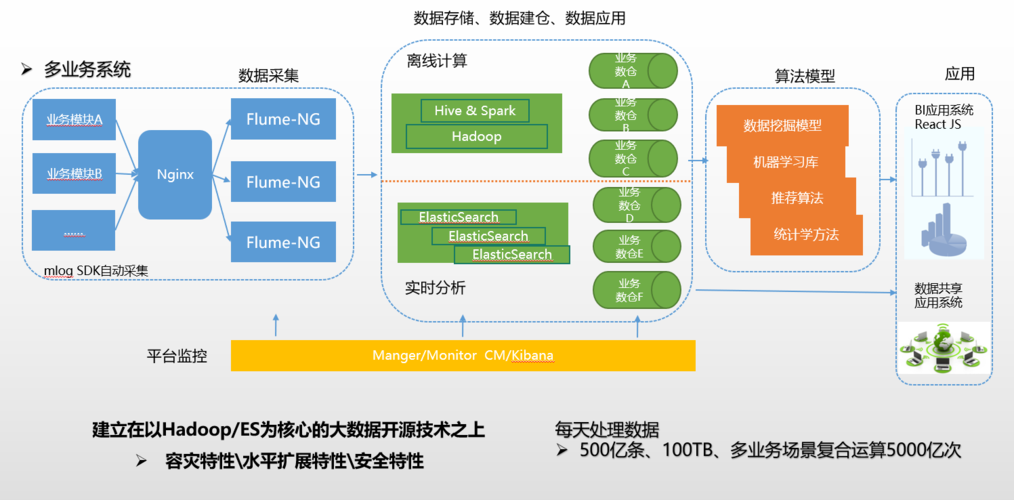

随着信息技术的迅猛发展,数据已经成为企业和个人不可或缺的资源,大数据时代的到来意味着数据量级的增长已经远远超出了传统数据库的处理能力,因此需要新的存储解决方案来应对挑战,本节将探讨大数据存储的关键概念和技术。
分布式文件系统
在大数据环境下,分布式文件系统是存储海量数据的基础架构,它允许数据跨越多个物理服务器进行存储,而对用户来说,这些数据就像存储在一个单一的地方一样。
hadoop distributed file system (hdfs): 它是最广泛使用的分布式文件系统之一,为hadoop框架提供高吞吐量的数据访问,非常适合大规模数据集的场景。
apache ceph: 一个开源的分布式存储系统,提供了对象、块和文件存储功能,支持自动数据复制和恢复。
nosql数据库
传统的关系型数据库在处理非结构化或半结构化数据时面临性能瓶颈,nosql(not only sql)数据库应运而生,它们设计用来横向扩展以支持大量数据。
键值存储(keyvalue stores): 如redis, dynamodb,适用于快速查找和存取数据。

文档数据库(document databases): 如mongodb, couchbase,能够存储json等格式的文档。
列族存储(widecolumn stores): 如cassandra, hbase,适合处理大量分布的列式数据。
图形数据库(graph databases): 如neo4j, janusgraph,专门用于存储网络结构数据。
数据湖
数据湖是一个大型仓库,用于存储大量原始数据,无论其来源、格式或模式如何,它支持数据的后续分析和提取。
apache hadoop ozone: 是hadoop项目的子项目,旨在提供可扩展的存储,以支持hadoop生态系统中的数据湖架构。
apache hudi: 提供了高效的数据湖更新和查询服务。
对象存储
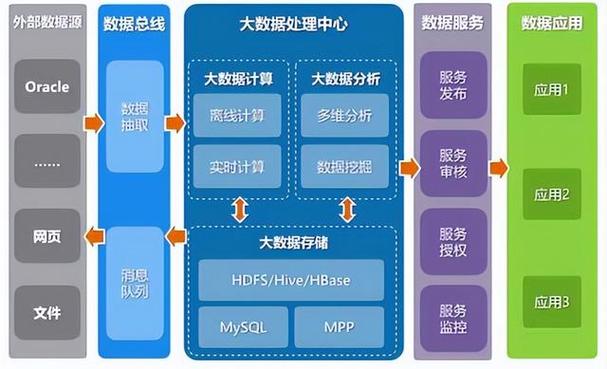
对象存储是一种扁平的结构,用于管理数据作为对象,每个对象都包含数据、元数据和全局唯一标识符。
amazon s3: 提供简易的web服务接口来随时从网络上任何位置存储和检索任意数量的数据。
openstack swift: 用于创建可扩展和冗余的对象存储。
数据压缩和编码技术
为了优化存储空间和提高数据传输效率,采用数据压缩和编码技术至关重要。
snappy: 由google开发的快速压缩和解压缩库。
lz4: 专注于解压缩速度的压缩算法。
相关问题与解答
q1: 为什么分布式文件系统比传统的本地文件系统更适合大数据环境?
a1: 分布式文件系统设计用来处理和存储分布在多台机器上的数据,它通过并行处理和容错机制来提高数据处理的速度和可靠性,相比之下,传统的本地文件系统受限于单台机器的资源,无法高效地处理和存储pb级别以上的数据。
q2: nosql数据库与传统的关系型数据库有何不同?
a2: nosql数据库通常不使用固定的模式,并且更加灵活地处理各种类型的数据,包括非结构化和半结构化数据,它们通常支持横向扩展,可以更容易地添加更多服务器来处理增加的数据负载,相反,传统的关系型数据库通常要求预定义的模式,并且在处理大量数据时可能面临性能瓶颈和扩展困难。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复