
大数据分布式处理框架与分布式执行框架
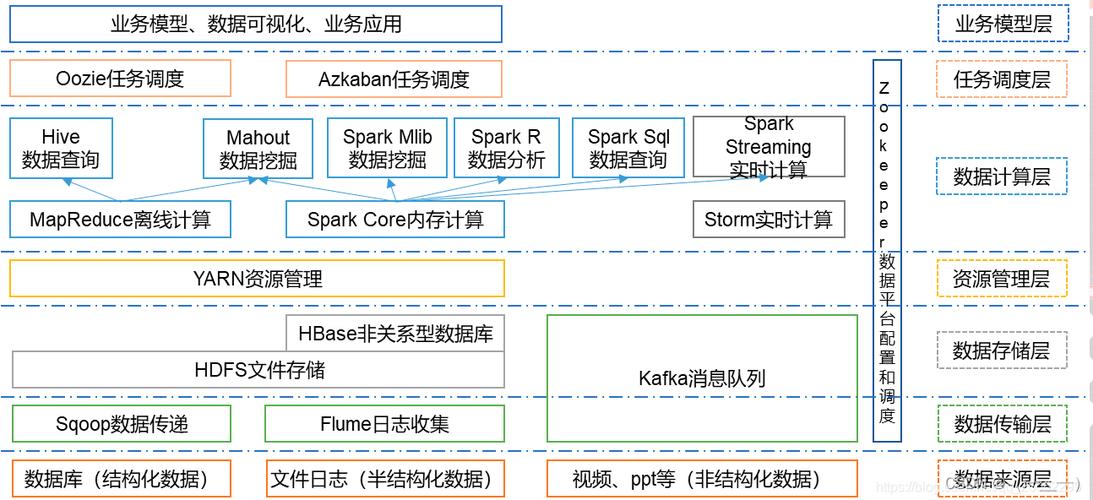

大数据处理通常涉及大量的数据和复杂的计算,单个服务器很难满足这种需求,分布式处理框架被设计用来在多个服务器上并行处理大数据集,以下是一些常见的大数据分布式处理框架及其分布式执行框架的概述:
Apache Hadoop
hdfs(hadoop distributed file system)
功能: 提供高吞吐量的数据访问,适合大规模数据集上的应用。
特点: 高度容错性,可以部署在廉价硬件上。
MapReduce
功能: 编程模型和一个用于并行处理大数据集的执行框架。
特点: 将任务分为映射(map)和归约(reduce)阶段,分别进行数据处理。
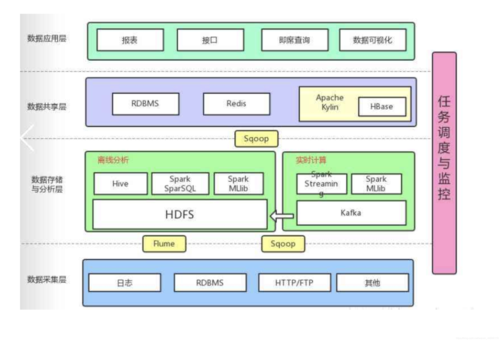
Apache Spark
弹性分布式数据集(rdds)
功能: 提供了一种高效的方式来跨集群节点分发和并行处理数据。
特点: 内存中集群计算,提高了迭代算法的处理速度。
spark核心组件
功能: 包括支持多种语言的api,如scala、java、python等。
特点: 支持批处理,交互式查询,流处理,机器学习等。
Apache Flink
datastream api
功能: 用于实时流处理和批处理。
特点: 支持事件时间处理和恰好一次状态一致性。
table api & sql
功能: 用于表结构和关系型数据处理。
特点: 兼容sql标准,易于使用。
Apache Storm
storm拓扑结构
功能: 用于实时数据分析。
特点: 保证每条消息都被处理,容错性好。
trident接口
功能: 对storm进行微批次处理。
特点: 提供了更高级的抽象来简化实时处理。
相关问题与解答
q1: hadoop和spark在处理大数据时的主要区别是什么?
a1: hadoop使用磁盘级运算,而spark使用内存级运算,这意味着spark在处理需要频繁读写中间结果的任务时,比如机器学习算法,可以比hadoop更快,对于不需要频繁操作中间结果的批量作业,hadoop可能更稳定且成本较低。
q2: flink如何处理流处理和批处理?
a2: flink通过统一的引擎处理流处理和批处理任务,它的核心是datastream api,可以同时处理流式数据和批数据,flink的流处理模型是基于事件时间的,能够处理乱序到达的事件,并且保证恰好一次的状态一致性,批处理在flink中是通过一组有限的流实现的,这使得flink能够无缝地在两种模式之间切换。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复