
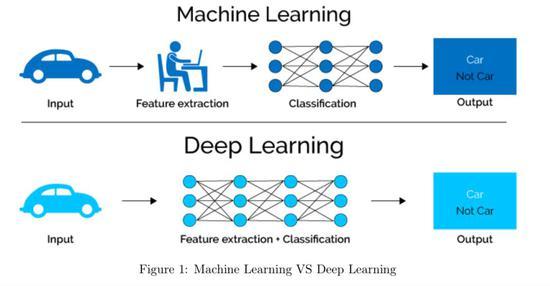
在机器学习中,处理因子类型的数据是一项基本且关键的步骤,因子水平(Factor Level)是指在分类变量中,不同类别的具体取值,在处理数据集中的性别字段时,’男’和’女’就是此因子的两个水平,在机器学习模型的训练过程中,正确处理这些因子水平对于模型的性能有着直接的影响,本文将详细解析如何在端到端场景下应用机器学习技术处理因子水平,并通过R语言展示具体的操作方法。

理解因子变量的创建
在R语言中,使用factor()函数可以创建一个因子变量,这个函数的基本用法包括以下几个关键参数:x,levels,labels, 和ordered。x是需要被转换的向量,levels是因子的可能水平,labels是用于显示的标签,而ordered则指示是否按照顺序对因子水平进行排序。
手动指定参考因子水平
在构建回归模型或进行统计分析时,我们可能需要手动指定一个参考的因子水平,在R语言中,可以使用relevel()函数来实现这一需求,该函数允许用户指定哪个水平作为参考水平,并据此重新排序因子向量。
因子水平的应用场景
1.数据预处理
缺失值处理:在数据预处理阶段,处理因子变量中的缺失值是一个重要步骤,使用factor()函数时可以通过设置exclude参数为NA来排除缺失值。
数据编码:连续的数字编码可以简化模型的训练过程,通过设置factor()函数的levels参数,可以确保每个类别被赋予一个唯一的数字标识。
2.模型训练
线性回归模型:在训练线性回归模型时,通过调整relevel()函数,可以设定哪个因子水平作为基线,从而影响模型系数的解释和模型的预测性能。
机器学习算法:在应用机器学习算法如随机森林或支持向量机时,正确设定因子水平可以帮助算法更好地理解和利用类别间的差异。
操作实例
假设有一个数据集包含“性别”和“职业”两个因子变量,我们可以使用以下代码对其进行处理:
创建示例数据
data < data.frame(gender = c('男', '女', '女', '男', NA),
job = c('工程师', '教师', '医生', '律师', '工程师'))
转换因子变量
data$gender < factor(data$gender, levels = c('男', '女'), labels = c(1, 2), exclude = NA)
data$job < factor(data$job, levels = unique(data$job))
查看处理后的数据
print(data) 在这个例子中,gender字段被转换为数值型因子,方便后续的模型训练,同时job字段也经过处理,确保所有水平都被包含。
通过对因子水平的精确控制和应用,可以显著提高机器学习模型在处理分类数据时的准确性和效率,无论是在数据预处理还是模型训练阶段,合理的因子水平设置都是至关重要的。
相关问题及解答:
1、Q: 如何确定因子水平的数量对模型性能的影响?
A: 可以通过交叉验证等方法评估不同因子水平设置下模型的表现,选择最佳的水平设置方案。
2、Q: 在哪些情况下不应该使用自动因子水平排序?
A: 当数据的天然顺序或者特定领域的知识表明某种排序方式更有利于模型解释和预测时,应避免使用自动排序。
【版权声明】:本站所有内容均来自网络,若无意侵犯到您的权利,请及时与我们联系将尽快删除相关内容!


发表回复